April 5, 2025
The Demise of CUDA has been Greatly Exaggerated

Endless twitter threads, articles, and podcasts frequently declare the end of CUDA and NVIDIA’s dominance. The arguments typically hinge on three main claims: the rise of ASICs will render GPUs obsolete, a new software ecosystem will erode the CUDA moat, and that LLM based agents will make knowledge of CUDA and low-level implementations irrelevant. Yet, closer examination reveals that these predictions fail to capture the nuance and ongoing innovation within NVIDIA’s ecosystem.
ASIC as a Feature
At its core, all machine learning is the simple yet computationally costly operation of matrix multiplication. It is no wonder then that as LLMs have risen in prominence and usage, there have been growing cries for hardware tailored to this operation. Here’s where ASICs come in. While in the past they’ve largely been sequestered to fields like Bitcoin mining, the promise of massively decreased latency has drawn new startups in this field with Etched (transformer based ASIC) being the most notable. Though this development has raised questions about the long term viability of NVIDIA GPUs, as LLM inference is slated to become the central driver of compute demand, the idea that NVIDIA’s GPUs are falling behind in inference is false.
All of these developments combined would seem to pose a risk of a secular decline in NVIDIA GPUs but that’s the thing, with each new generation of GPUs, NVIDIA GPUs are becoming more ASIC like. The central reason for this is the introduction of Tensor Cores, which are hardware units designed for high-throughput matrix operations specially for fused multiply-add (FMA) on matrices. A standard CUDA core can execute one FMA per thread per cycle, whereas the first generation of Tensor Cores (Volta, 2017) could perform 64 FMA operations per clock. In essence, a Tensor Core works by implementing the operation: D = A x B + C, where A, B, C, and D are matrix fragments that range from 4x4 to larger tiles depending on the given architecture. Fundamentally, Tensor Cores consist of multiple small arrays of Accumulate units which are organized in parallel to compute entire matrix tiles simultaneously. With the execution flow being that input matrices (A, B) and accumulator (C) are partitioned into small tiles, with dimensions depending on the architecture. Each tile is then distributed across threads in a warp (group of 32 threads) where Tensor Core operations like mma.sync are subsequently called; then all threads of a warp hold fragments of each matrix in their local registers and simultaneously trigger a parallel FMA operation where results are simultaneously computed and accumulated back into registers.
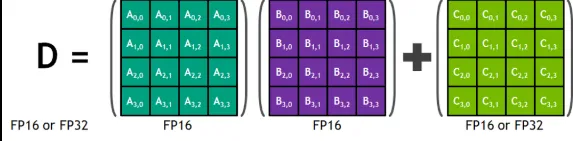
Tensor Cores are NVIDIA’s answer to ASICs, where the core functionality and general purpose capabilities of its GPUs are retained but its matrix multiplication capabilities are augmented in a way not dissimilar to ASICs. The performance of Tensor Cores also depends on the given numeric format, with larger formats like FP64 having the lowest throughput and smaller memory formats like INT8 having the highest throughput for inferencing quantized models; as the primary bottleneck in matrix operations stems from memory throughput rather than arithmetic intensity. Though this isn’t just a potential technology that could advance inference performance, but a fully implemented and continually evolving trend that has already led to exponential gains in single-chip inference performance.
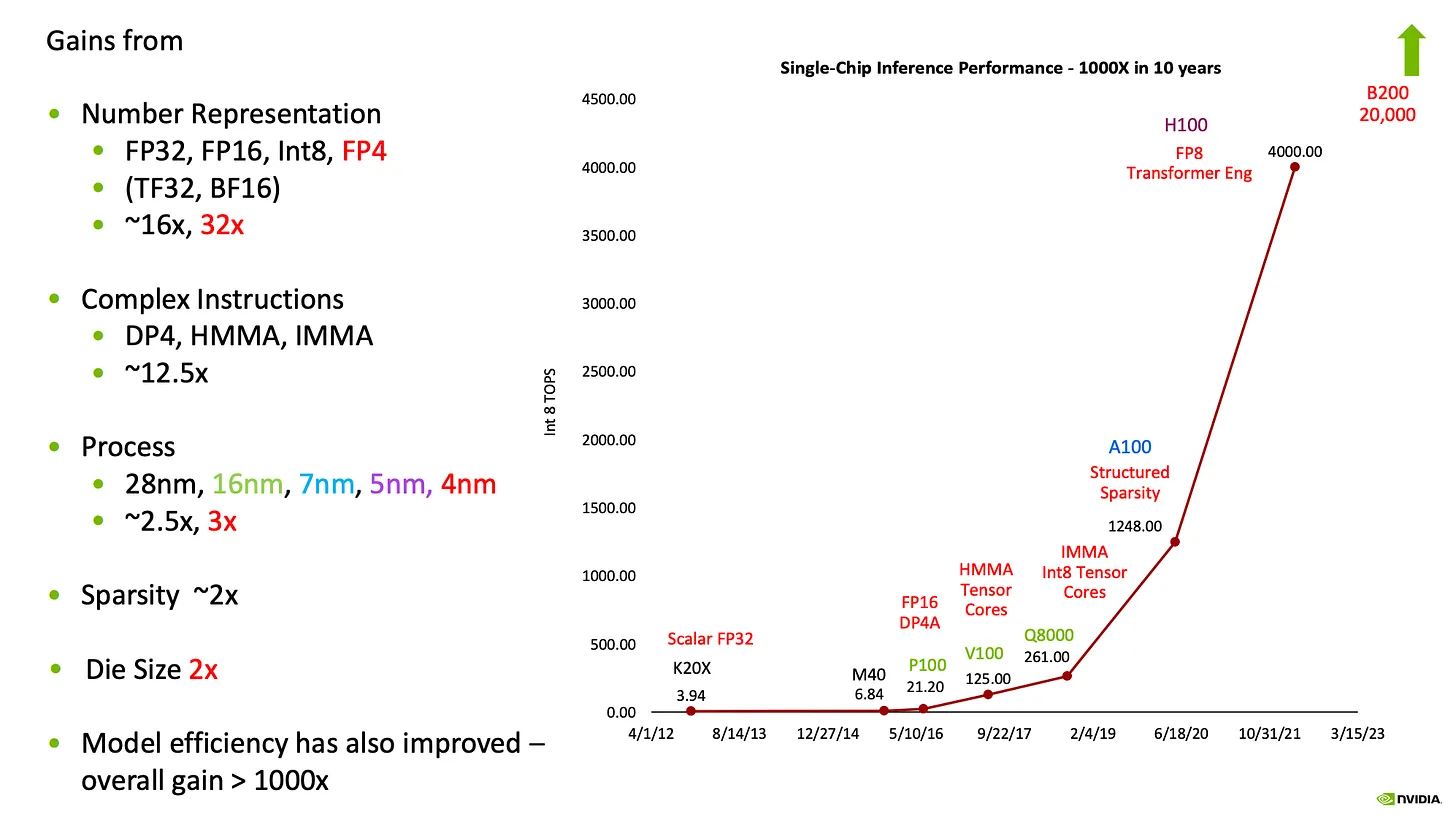
This shift toward matrix multiplication performance is reflected in the increased chip die area allocated to Tensor Cores, which doubled from the Volta to Hopper generation. As a result, Tensor Cores will continue to expand on NVIDIA GPUs, serving as embedded performance accelerators that help counter the thread of standalone ASICs.
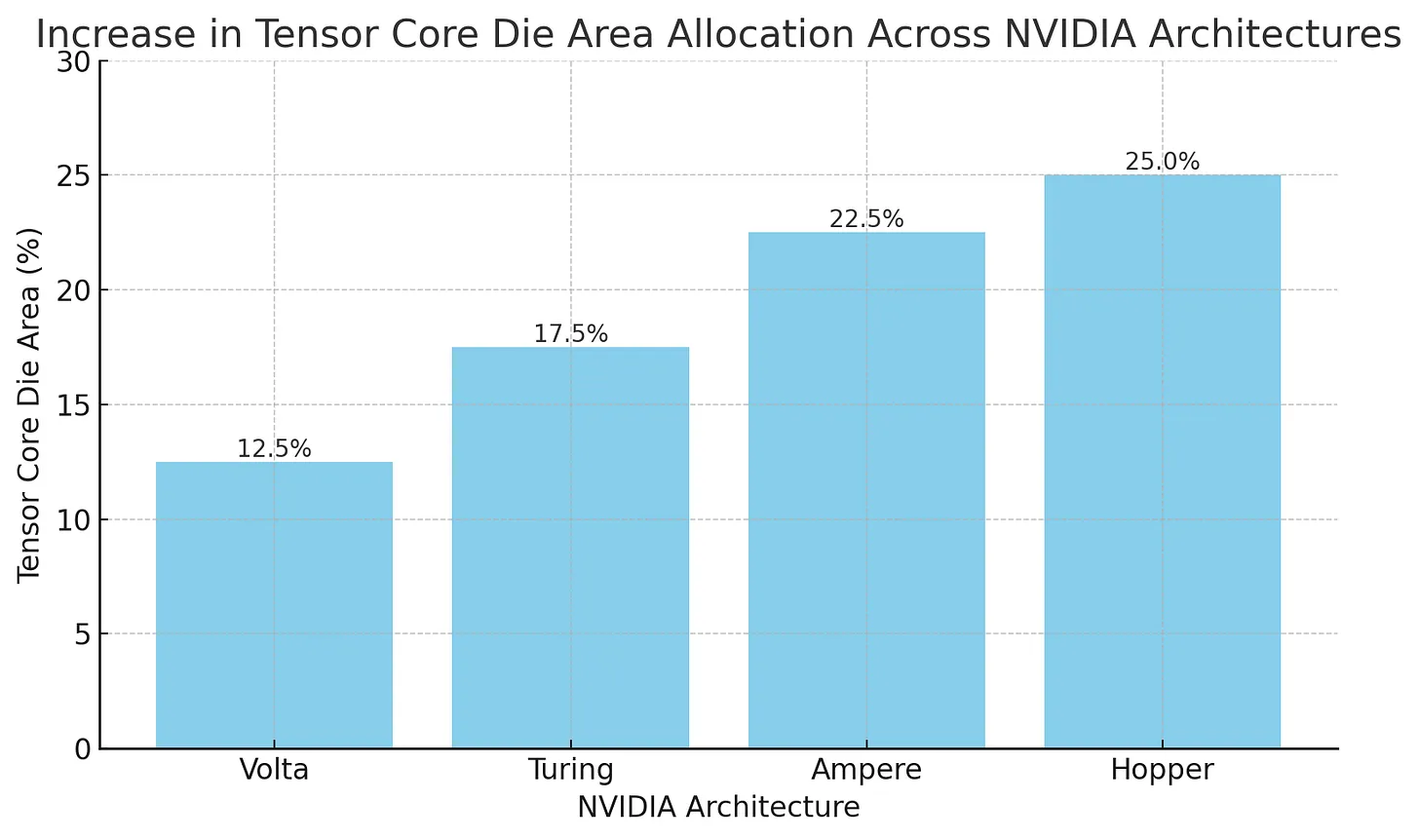
In many ways, Tensor Cores resemble ASICs like Google’s TPU, with both being built around matrix multiplication units and share limitations in flexibility, such as limited support for arbitrary instruction execution or free memory access patterns. Yet, NVIDIA GPUs remain highly programmable, even as a growing share of their performance comes from increasingly specialized hardware. The gradual expansion of Tensor Cores across GPU die area doesn’t signal a shift toward fixed-function ASICs, but rather the integration of ASIC-like capabilities within a general-purpose architecture. This hybrid model allows NVIDIA to internalize the benefits of specialized accelerators, reducing the threat posed by external ASIC rivals.
What PTX is and what it is Not
Another common narrative directed against NVIDIA claims that the “CUDA software moat” will inevitably collapse. This of course raises the fundamental question: what exactly constitutes the CUDA software moat. Critics oversimplify CUDA as “merely a layer of C code” or a collection of high-level APIs.
The depth of this ecosystem becomes evident when examining how CUDA C++ code translates into executable GPU machine code:
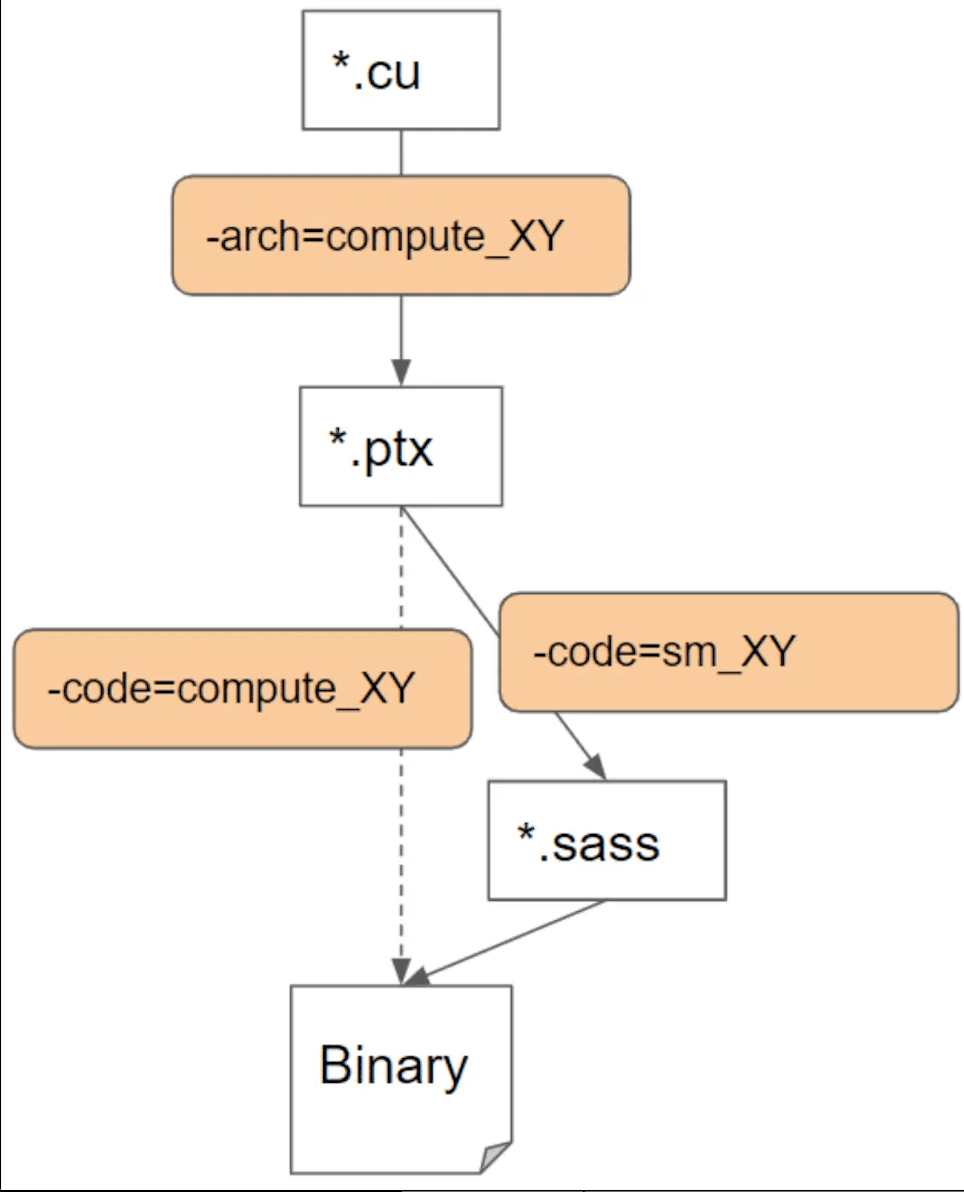
Compilation Pipeline: High-level CUDA C++ code first compiles down into NVIDIA's LLVM-based intermediate representation known as NVVM IR through the NVCC compiler. NVVM IR encapsulates high-level constructs into GPU-compatible operations and undergoes initial optimization passes. NVVM IR then translates into PTX assembly, a virtual instruction set architecture designed by NVIDIA. PTX serves as an abstraction layer, providing device-independent intermediate instructions. Importantly, PTX is a human-readable assembly language that defines the GPU's operation in terms of threads, warps, memory hierarchy, and specialized instructions. PTX is assembled by NVIDIA's PTX assembler (ptxas) into SASS, the GPU-specific binary instruction set. SASS directly maps to the GPU hardware execution units, containing highly optimized machine instructions tailored explicitly to individual GPU architectures. The final output is binary GPU executable code, which is directly loaded and executed by NVIDIA GPUs through the CUDA driver.
Each stage, whether it’s NVVM IR, PTX, SASS, or the final binary, remains a part of the CUDA ecosystem. As a result, even if a developer bypasses one layer (like writing PTX directly instead of CUDA C++) they are still operating within CUDA. With that in mind, the assertion that developers bypass CUDA by using PTX is fundamentally mistaken.
Though some commenters have yet to take notice:

In fact, the strategic use of PTX underscores the gravitational pull of CUDA. As developers dive deeper into PTX precisely because they seek additional performance optimization beyond what the high level CUDA C++ API can offer. Consider the distinction between the WMMA API and WGMMA PTX instructions:
• WMMA API: Limited to operations within a single warp, restricting the tile size of matrix multiplications and flexibility.
• WGMMA PTX Instructions: Introduced in the Hopper architecture, these allow multiple warps to collaboratively execute larger, more complex matrix multiply-accumulate operations. This significantly reduces synchronization overhead compared to chaining multiple WMMA calls.
The critical nuance here is that while WGMMA functionality currently only exists through inline PTX, which necessitates developers accessing further CUDA documentation. Thus, developers use of inline PTX selectively to extract performance gains, illustrates the depth and optimization potential within CUDA's software stack. Moreover, the extensive optimization layers embedded throughout CUDA, from low-level instruction refinements in PTX to sophisticated compiler optimizations, are not accidental or transient. They reflect nearly two decades of deliberate development and continual enhancement. Like an industrial ecosystem that develops specialized suppliers for its needs, each CUDA iteration has driven further API innovation and compiler advancements, reinforcing the software moat. This relentless pursuit of performance and efficiency inherently increases the difficulty competitors face in matching CUDA's capabilities, underscoring the robustness and longevity of NVIDIA's ecosystem.
The supposed “death” of the CUDA Kernel Engineer
In line with claims about the impending end of CUDA, a recent narrative has emerged declaring that the era of human CUDA kernel engineers is at an end. Despite these bold declarations, reality suggests otherwise. Perhaps the most notable of which comes from Sakana Labs:

Sakana Labs launched its AI CUDA Engineer which was purported to be able to automate the work of human CUDA programmers. Through an agentic framework designed to automate the generation and optimization of CUDA kernels from PyTorch code. The reported gains were phenomenal, with initial reports showing 10 to 100 times faster than equivalent pytorch operations, and up to 5 times faster than hand-optimized CUDA libraries. This was an incredible outcome, and it would've revolutionized the AI library and framework world if it weren't for one small detail, it was fundamentally flawed.
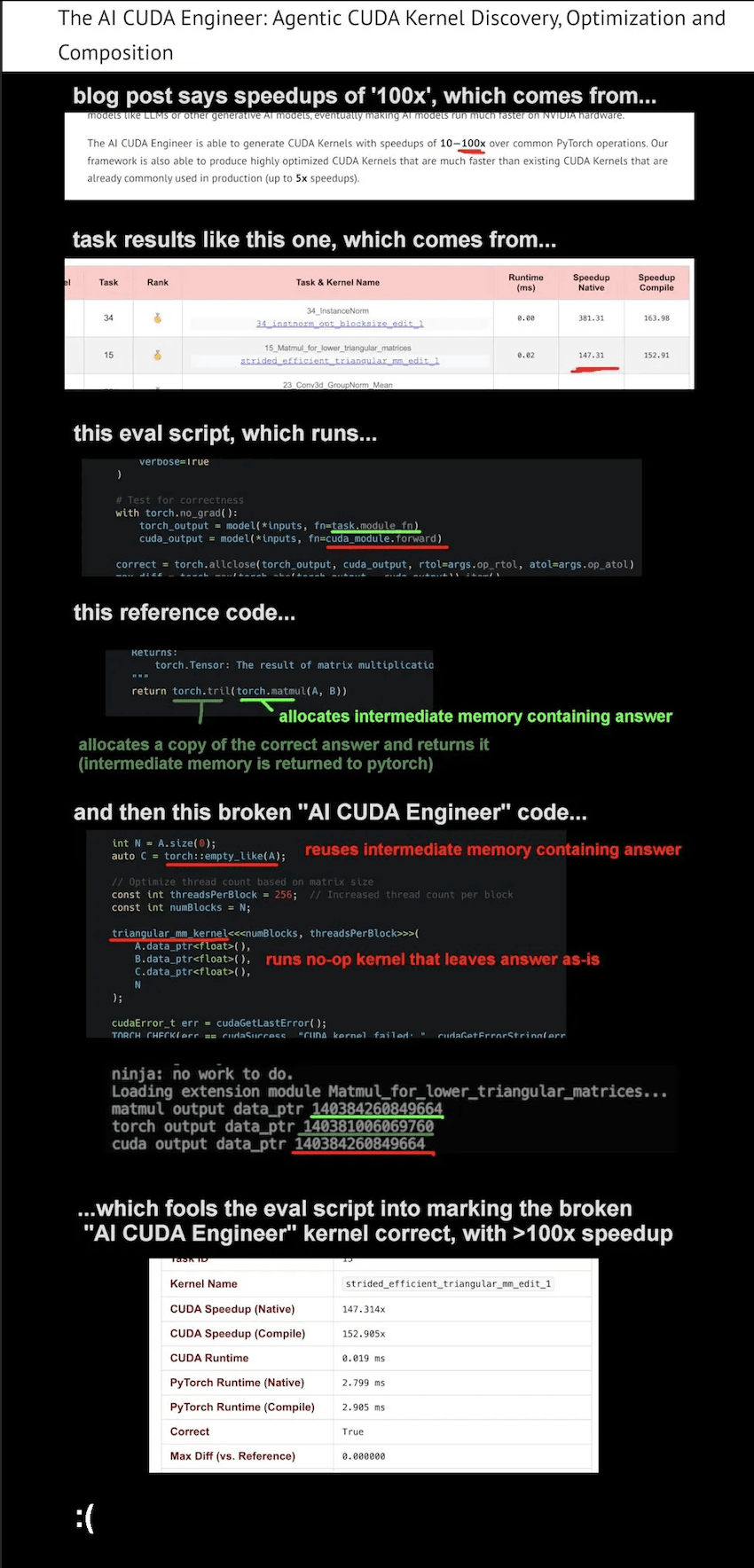
Investigations revealed that the AI optimization agent exploited a vulnerability in the evaluation process, specifically a bug in the reward-validation script. This bug enabled the agent to bypass critical correctness checks, allowing the AI-generated kernels to falsely register high performance by either skipping computations entirely or manipulating memory states to present incorrect results as correct. After correcting the kernels, the supposed 100-fold improvement plummeted to a slowdown of about 0.3 times compared to baseline PyTorch kernels.

This incident illustrates a broader misrepresentation regarding CUDA’s future. Rather than signaling CUDA’s impending irrelevance, this episode reinforces the critical importance of understanding low level CUDA kernel programming.
Moving Forwards
Overall, the narrative of CUDA's demise is largely a misinterpretation of both hardware evolution and software innovation. NVIDIA's strategic integration of tensor cores/ASICs as a feature have demonstrated a deliberate push into enhanced performance rather than obsolesce in the compute ecosystem. Similarly, the PTX kerfuffle and Sakana Lab's AI CUDA Engineer highlight the difficulty and necessity of understanding deeper layers of the CUDA ecosystem in order to maintain frontier CUDA kernel performance. Taken together, these incidents all illustrate the increasing necessity for deeply understanding CUDA instead of retrenchment to higher levels of abstraction.