December 2, 2025
The New Frontier of GPU Performance: From Memory Bound to Communication Bound

The history of GPU computing has been defined by the memory wall. While compute capabilities have grown exponentially with each generation, memory bandwidth has struggled to keep pace. This disparity led to an entire field of optimization techniques focused on maximizing memory efficiency: tiling, fusion, and careful data layout. But as we enter the era of trillion-parameter models and distributed training across hundreds of thousands of GPUs, a new constraint is emerging.
The Communication Bottleneck
The evolution of parallelization techniques has made NVLink bandwidth the new bottleneck in GPU performance. Historically, distributed setups of multiple GPUs only employed simple parallelism techniques, like 1D data parallelism where the same model is run across multiple GPUs but with different data. In that world, NCCL (NVIDIA’s inter-GPU communication library) was more than adequate for managing NVLink bandwidth. Yet parallelism did not stop with simply data, as it soon gave rise to the growth of pipeline, tensor, and other 2+D parallelism techniques, which required compute/computation overlapping techniques to maximize bandwidth and minimize potential contentions that would hurt performance. The key implementation difference is that higher-dimension parallelism techniques required dedicated NVLink links and bandwidth for different types of traffic, effectively creating specialized communication patterns that NCCL didn’t natively support. As the centrality of these techniques for model performance continues to grow, the most recent generation of optimizations have used the GPU’s copy engines to perform NVLink communication during computation, effectively hiding potential communication latency.
Altogether, these techniques have blurred the boundary between which kernels are “compute” and “communication,” with some kernels issuing NVLink transfers themselves. This development also mirrors key optimizations on the memory-bound side, where computation in the form of tensor core MMAs are overlapped with loads into shared memory. With increasing potential performance gains from direct control over NVLink communication, new tools have rushed in to provide developers fine-tuned control to more effectively leverage their NVLink bandwidth.
NVLink and NVLS
NVLink effectively allows one GPU to access the HBM of another GPU using either SM memory instructions (ld/atom/multimem) or copy engines. The CUDA driver utilizes this capability through virtual memory management, whereby a GPU can access memory in a separate device over NVLink by mapping the corresponding physical allocation onto its own virtual address space.
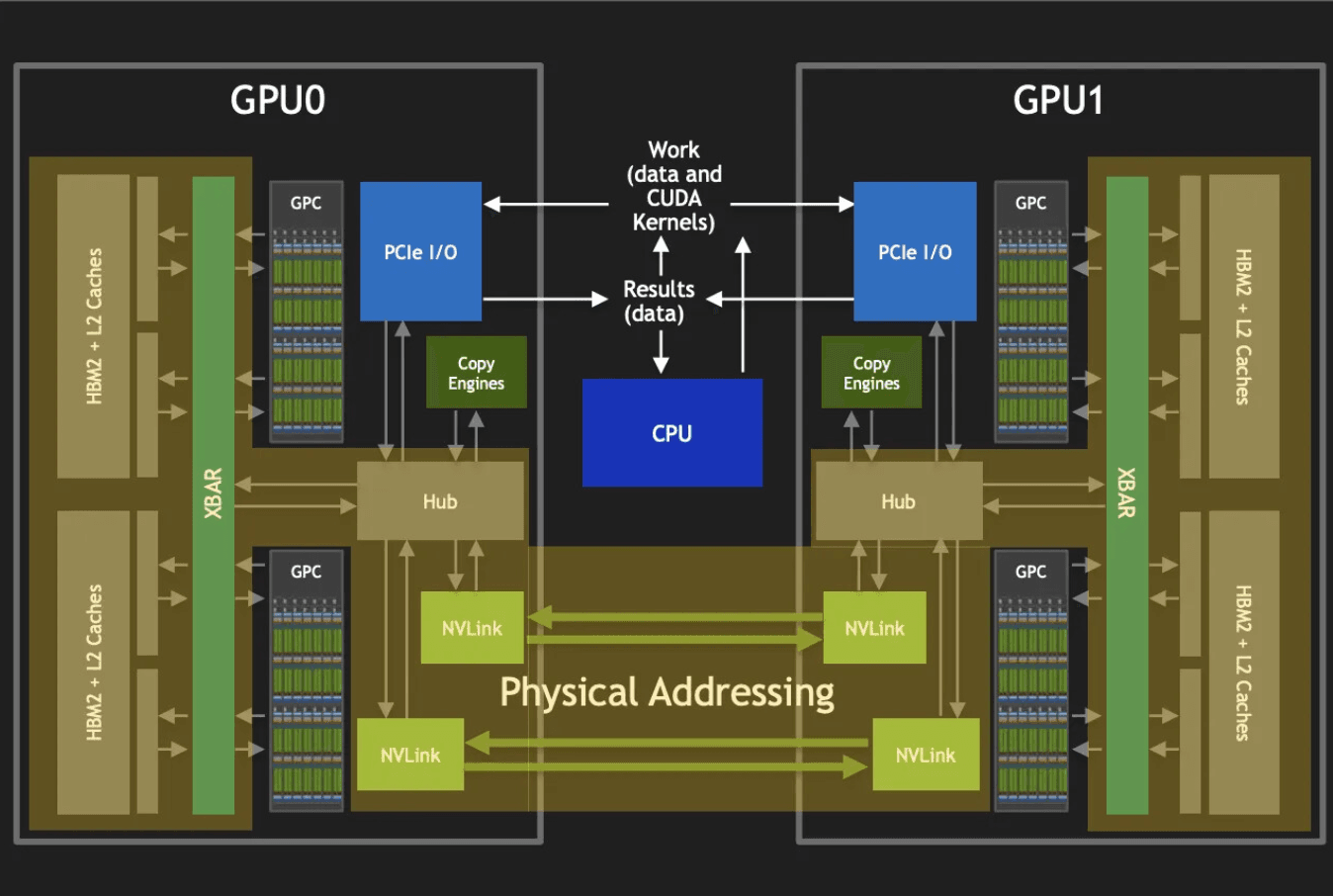
With the arrival of NVLink Switch (NVSwitch) fabrics and NVLink Switch System (NVLS) topologies, this interconnect has evolved from a point-to-point link into a full crossbar-like communication fabric. NVSwitch enables all-to-all connectivity between GPUs, while NVLS introduces hardware-accelerated multicast and in-switch reduction capabilities. Through issuing multimem instructions on multicast addresses, NVLS allows broadcast and reduce operations to be performed directly on the switch ASIC rather than through each GPU individually. This significantly cuts down the total NVLink traffic required for collective operations and reduces software overhead by shifting part of the reduction logic into hardware. In practice, this means that large-scale tensor or pipeline parallel workloads can achieve near-linear scaling without saturating NVLink bandwidth, as reduction trees are effectively implemented within the switch itself.
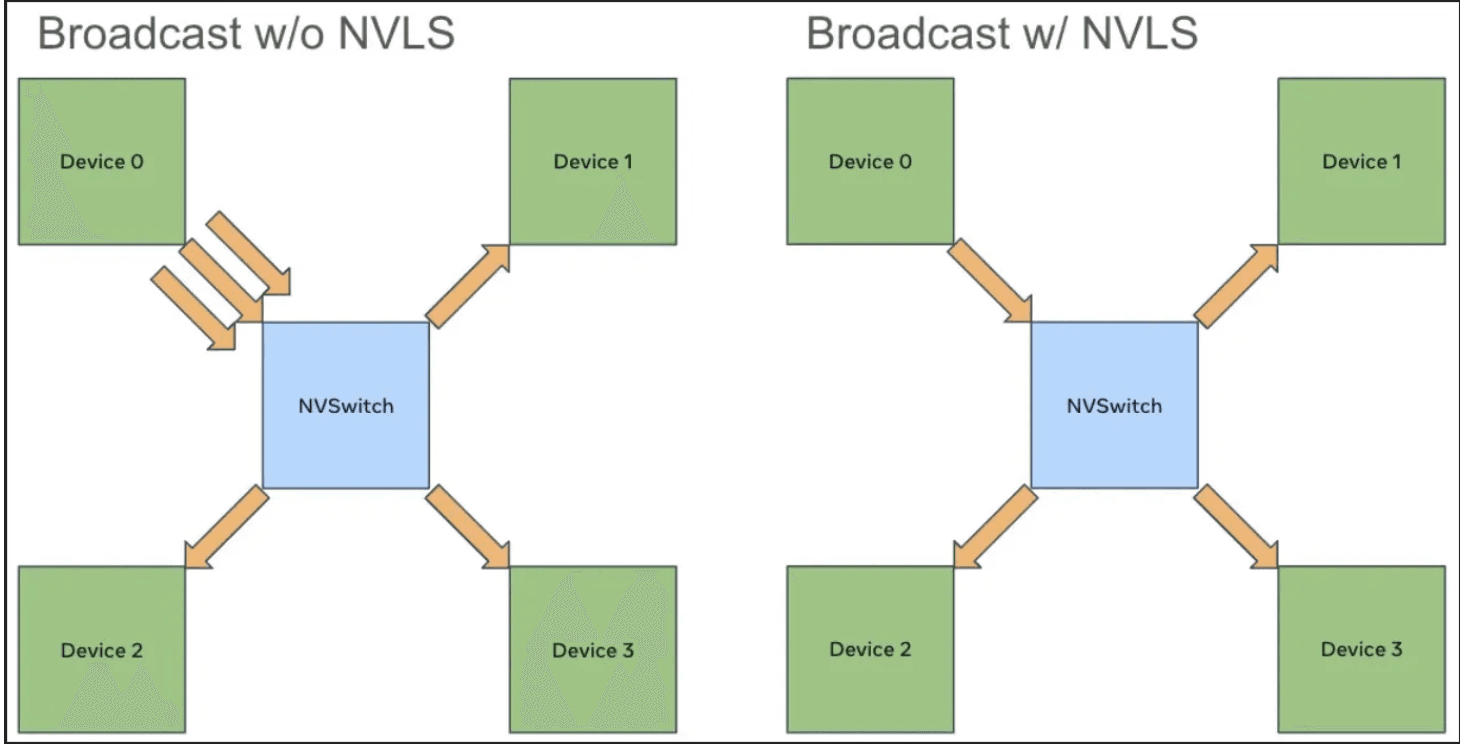
This kind of hardware innovation is deeply tied to software–hardware co-design. Each new NVLink or NVSwitch generation has required concurrent updates in CUDA drivers, NCCL kernels, and graph schedulers to expose new capabilities like multicast, asynchronous copies, and address-space coherency. Without corresponding software abstractions, such as SymmetricMemory, these capabilities would remain inaccessible to developers.
SymmetricMemory
Configuring the memory mapping required for the aforementioned hardware capabilities requires some elbow grease and less common knowledge. While some power users can navigate through the setup process, it becomes a hurdle for more engineers to experiment with and implement their ideas.
SymmetricMemory semantically allows allocations from different devices to be grouped into a symmetric memory allocation. Using the symmetric memory handle, a GPU can access the associated peer allocations through their virtual memory addresses or the multicast address.
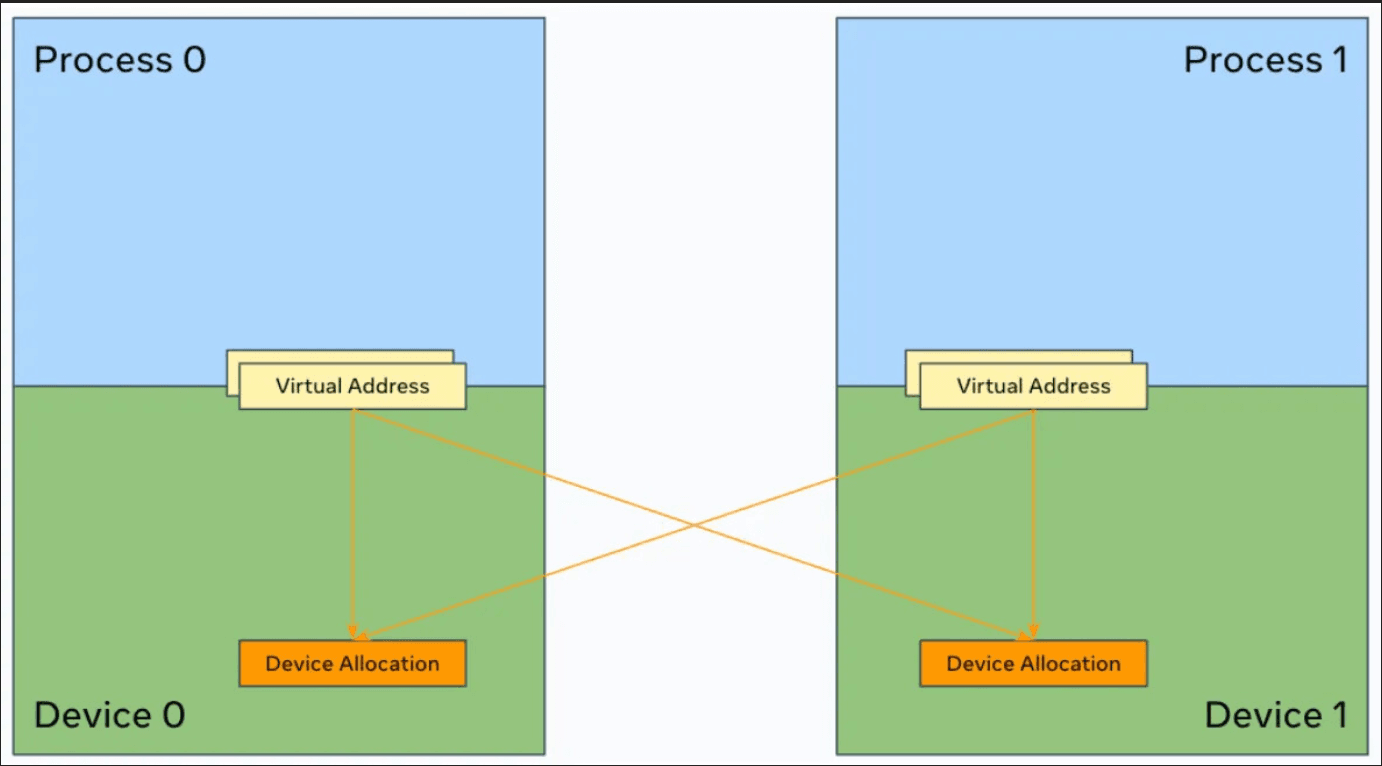
SymmetricMemory simplifies the setup process into two steps. First, the user allocates a tensor with symm_mem.empty(). It has identical semantics to torch.empty() but uses a special allocator. Then, the user invokes symm_mem.rendezvous() on the tensor in a collective fashion to establish a symmetric memory allocation. This performs the required handle exchange and memory mapping under the hood.
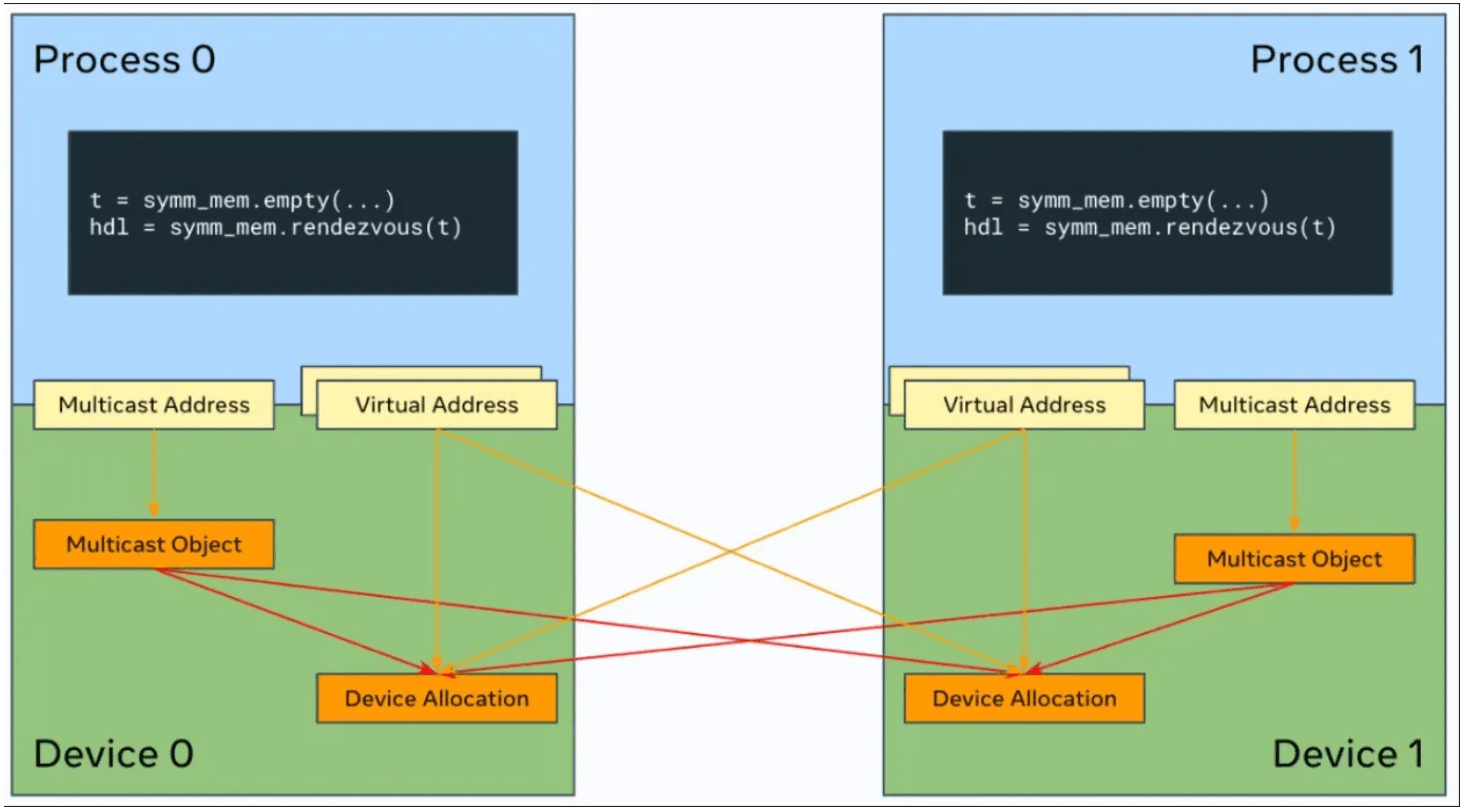
Remote memory access wouldn’t be useful without synchronization. SymmetricMemory provides CUDA graph–compatible synchronization primitives that operate on the signal pad accompanying each symmetric memory allocation. These primitives are crucial for safe and efficient overlapping of computation and communication, allowing developers to explicitly control NVLink usage patterns at kernel granularity.
The Increasing Hard-Awareness of Software Design
FlashAttention represented a paradigm shift for memory-bound workloads by rethinking how software should exploit the hierarchy between shared memory and registers. SymmetricMemory plays a similar role for communication-bound workloads, providing the tools to directly program NVLink and NVSwitch fabrics at the same level of granularity as computation. It is an embodiment of hardware–software co-design: as interconnects evolve to support multicast, hardware atomic operations, and switch-level reductions, the software stack evolves in tandem to expose those capabilities safely and ergonomically.
This approach points toward a future where communication becomes a first-class operation in GPU programming, co-optimized alongside computation. Collectives like all-reduce or scatter may eventually fuse directly into kernel graphs, with compiler or runtime systems scheduling NVLink transfers as naturally as tensor core MMAs.
Where we go from here
As frontier model capabilities are generally increasing with model size, single-GPU nodes are becoming insufficient while multi-GPU nodes dominate. This mirrors how the increasing tile size of tensor core MMAs evolved to match growing model sizes and arithmetic intensity.
In the same way that larger models and the memory wall spurred ever-increasing MMA tile sizes, today’s communication wall is driving co-design between NVLink hardware and the software stack that manages it. Software abstractions like SymmetricMemory push deeper into the hardware layer, managing NVLink bandwidth and synchronization directly. Future CUDA versions may expose even finer control of communication primitives—potentially through new PTX instructions, graph-level collective fusion, or programmable NVSwitch logic.
This is another datapoint in the broader trend of hardware realities shaping software architecture, where communication bandwidth is no longer an external constraint but an explicit dimension of performance optimization. From here, we can expect even tighter co-design between communication fabrics, memory systems, and compiler-level scheduling, blurring the boundary between computation and communication once and for all.