Outperforming cuBLAS on Blackwell
Blackwell Features: Tensor Memory
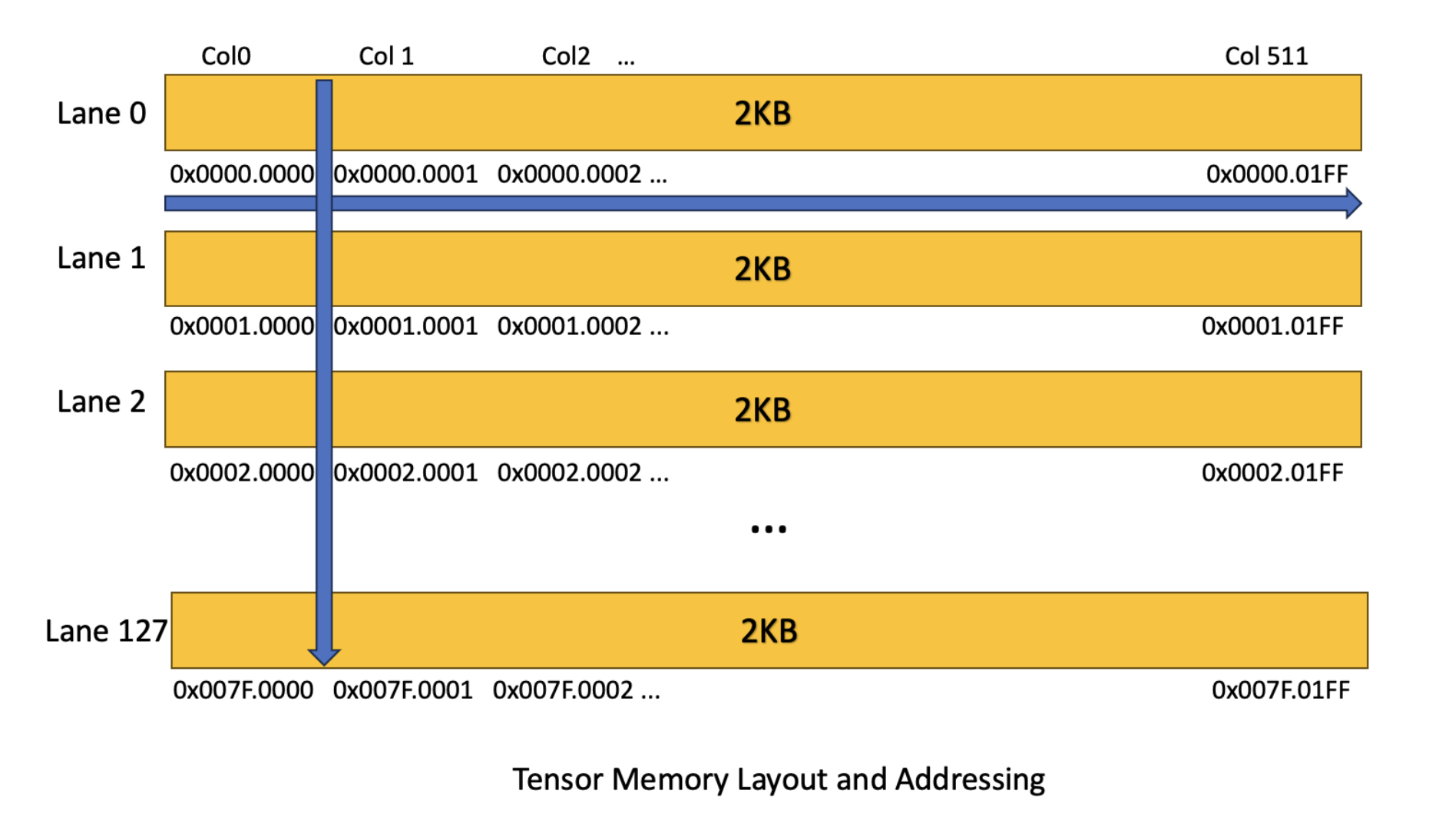
Tensor Memory (TMEM) is a new form of on-chip memory that is dedicated exclusively for use by Tensor Cores. As Hopper and prior generations held matrix fragments in register files, this led to significant register pressure where register file space became a critical bottleneck for performance. With the introduction of Tensor Memory, for an MMA instruction, Operand A must be in TMEM or SMEM, B must be in SMEM, and the accumulator must be in TMEM. As a result, 5th generation MMA instructions no longer require any register file space for data, which reduces the register pressure from these operations. Consequently, this lack of registers further decouples MMA from the CTA’s main execution flow which provides further opportunities for pipelining. Overall, the introduction of TMEM is another data point towards the trend of general-purpose computational resources being turned into specialized and ML application specific resources, further ASIC-ification if you will. As seen in the image above, TMEM is organized in a 2 dimensional fashion with 512 columns and 128 rows/lanes, with 256KB per SM.
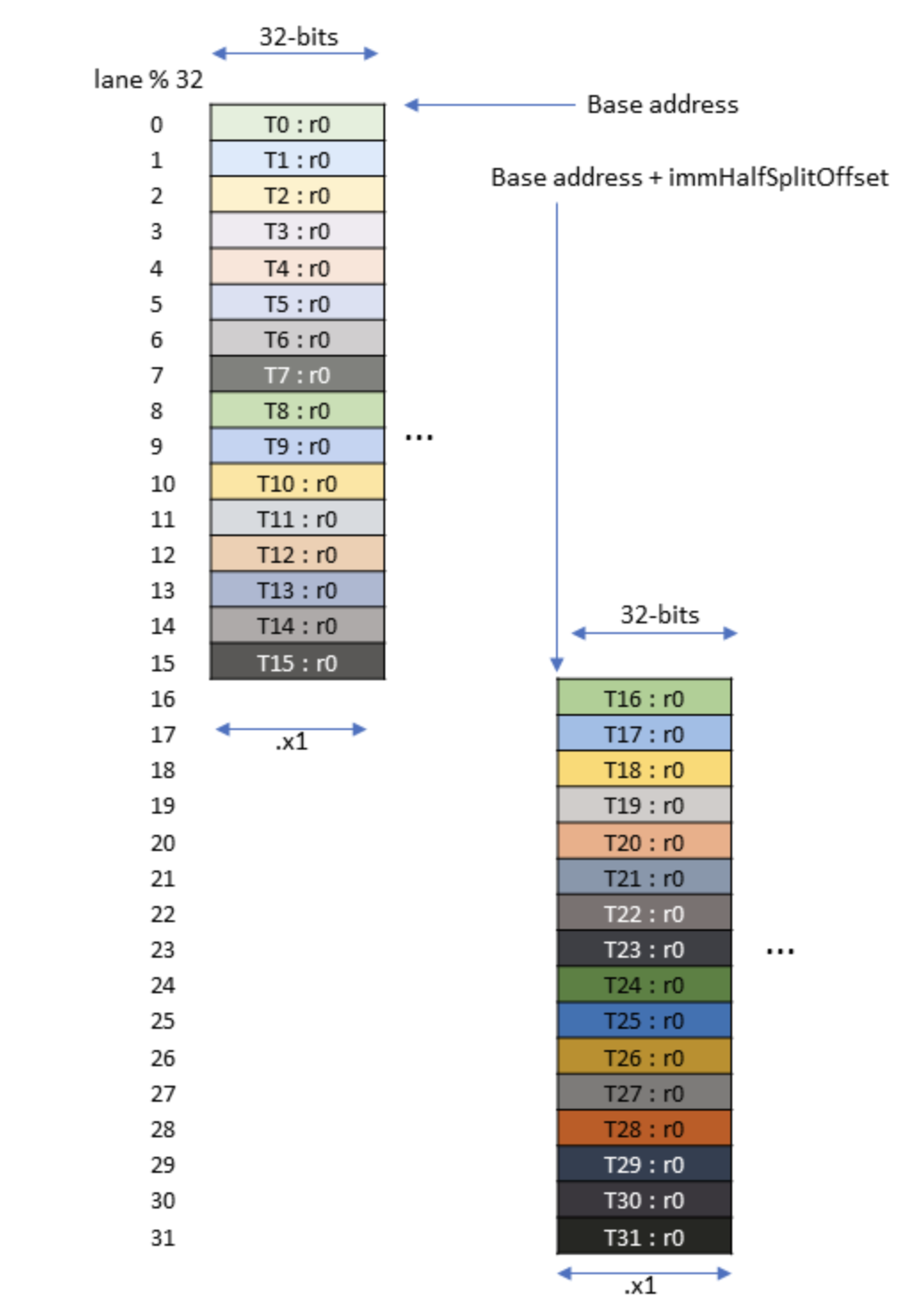
Additionally, TMEM has to be allocated dynamically using the tcgen05.alloc PTX instruction where allocation is in units of columns. Also data in TMEM is only used for MMA operations or data movement, so all post and pre-processing will occur outside of TMEM.
5th Generation Tensor Cores

The new 5th generation MMA instruction or tcgen05.mma takes a different form than Hopper’s WMMA or WGMMA as it now allows for a 2-CTA case. Also registers are no longer specified in the PTX instruction and operands a and b are shared memory descriptors similar to the ones used in WGMMA. The main difference is that tcgen05.mma expects an instruction descriptor that contains details regarding data type and sparsity.
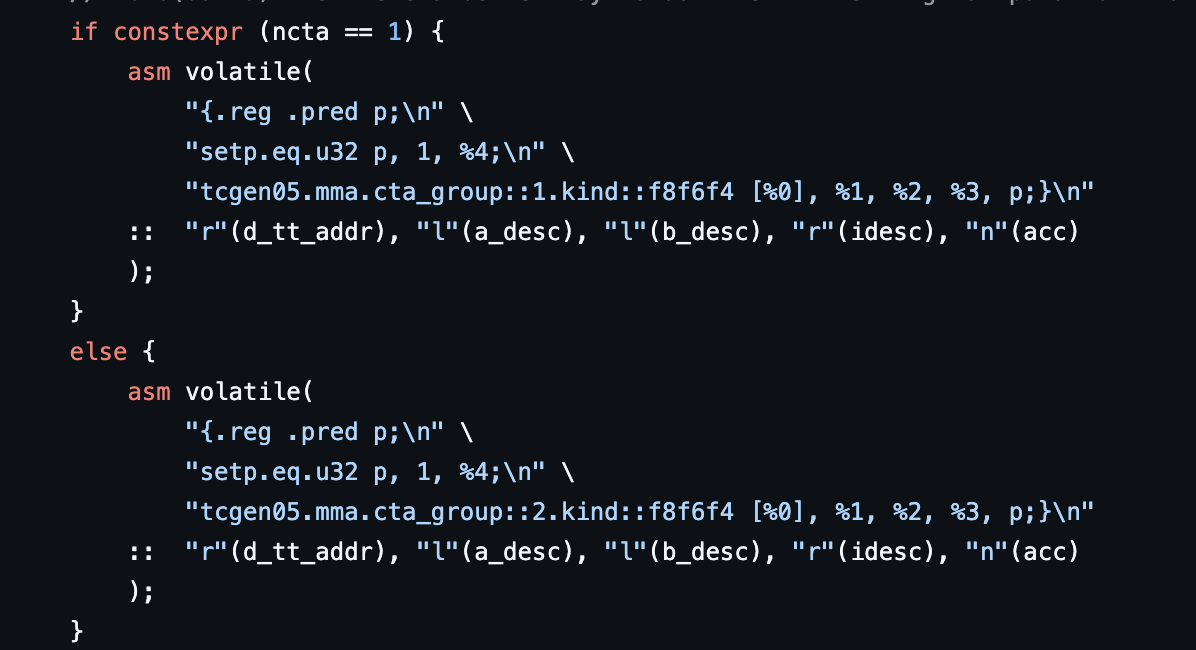
Above is my specifc tcgen05.mma PTX instruction implementation.
2SM MMA
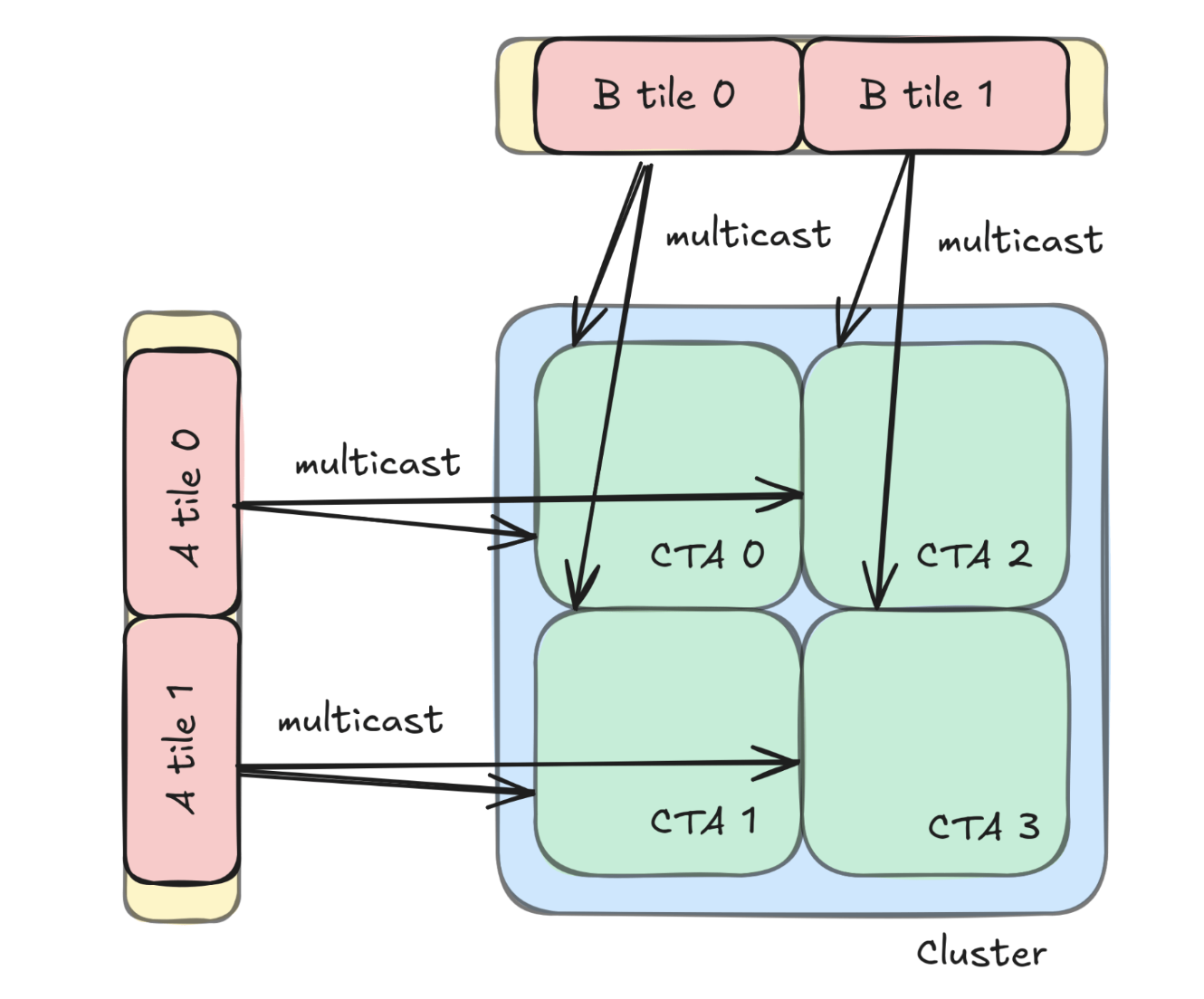
The rationale for extending MMAs to 2 CTAs is that CTA tile loads are often redundant, where the redundancy is occurring at the level of tiles as opposed to specific elements. In order to mitigate this, we can now group CTA’s into a 2x2 cluster where SMs can access each other’s shared memory, as opposed to having to load the tile from global memory and then broadcast that memory to its neighbors in the group. This method of multicasting can scale further but for now we will be using a 2x2 cluster where each CTA loads half of its tiles and gets the rest from its peers.
Hilbert Curve Scheduling
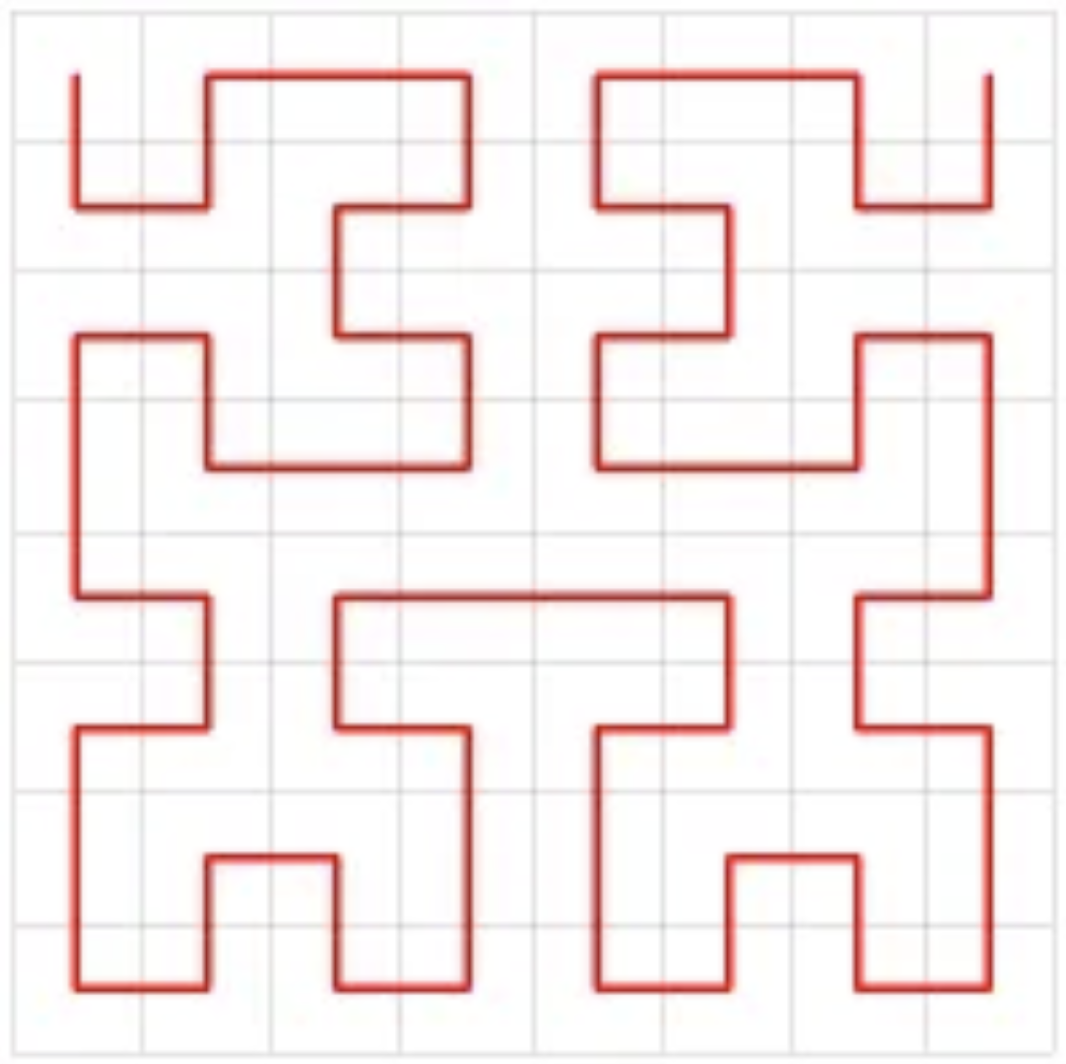
Furthering on this concept of working at the CTA level of granularity, we can schedule output tiles of SMs in a Hilbert curve schedule in order to increase our L2 cache hits within the same tile group. Hilbert curve is a space-filling curve that covers all cells within a matrix and ensures that it visits “nearby” cells together. In a sense this pattern is optimizing spatial locality, as a result consecutive tiles will be scheduled at the same time.