Outperforming cuBLAS on B200
Leveraging Blackwell Features for SOTA General Matrix Multiplication Performance
This article will outline iteratively implementing Blackwell features to optimize a matmul kernel in Brain Floating Point 16 (bf16) on varying matrix shapes on a B200 NVIDIA GPU. Our final kernel reaches 106% of cuBLAS's performance on M=N=K=8192. These optimizations arise from the increasing asymmetric hardware scaling of tensor core performance relative to memory bandwidth and other general purpose computation units on NVIDIA GPUs. We will begin with a brief summary of features new to Blackwell as well as B200 specifications then begin iteratively optimizing our matmul kernel.
Blackwell Architecture

The main new hardware features in Blackwell data-center GPUs are the introduction of Tensor Memory, Cluster Launch Control, and the 5th generation MMA instruction that enables MMA's spanning across peer CTAs.
Tensor Memory
Tensor memory arises from issues with the Hopper architecture. Hopper MMA instructions (WMMA and WGMMA) computed operands and stored accumulator results in the register file, namely in the registers of each thread respectively. The issue with this architectural choice is that many other operands and instructions also require the usage of the register file, with index calculations being the most notable, which leads to immense contention for registers between MMA operands, results, and instructions. Overall this harms performance as operands are spilled into more expensive memory regions like local memory which increases the latency of fetching these operands for operations. With Blackwell datacenter GPUs like the B200, MMA results are now accumulated in a new region of memory called tensor memory, instead of registers.
Lane (2KB each)Addressing directionThe tensor memory region is per SM, with tensor memory being organized as a 2-dimensional matrix that is 128 lanes (rows) and 512 columns in size. Each cell within this matrix is 32-bits or 4-bytes in size. Making the total memory capacity:
Another key detail is the access pattern of tensor memory.
Lane (2KB each)Warp boundaryAs opposed to other memory regions, tensor memory requires an entire warpgroup (4 warps) for full access of all lanes and columns, also the warpgroup must start at a warpgroup aligned index (multiple of 4). With each warp in the warpgroup being responsible for accessing 32 lanes. Therefore an entire warpgroup is required for the epilogue stage of matrix multiplication for writing computed values from tensor memory back to HBM. Another notable detail is that tmem must be deallocated by the kernel explicitly, as it is managed by the programmer, as opposed to smem that will be automatically deallocated.
Cluster Launch Control
Cluster Launch Control (CLC) is a Blackwell hardware mechanism that gives CTAs the ability to cancel queued CTAs that haven't begun executing yet and steal their work by taking the cancelled CTA's index. Unlike non-CLC persistent kernels that launch as many CTAs as there are SMs, CLC kernels launch as many CTAs as there are output tiles. This work stealing approach allows for CTAs to dynamically receive the next tile to work on as opposed to static assignment. Overall this improves load balancing as CTA run-times can exhibit variability so CLC can dynamically adjust for such variability via scheduling.
2-CTA MMA
Blackwell tensor cores can be used with the new tcgen05.mma PTX instruction. One new feature of tcgen05.mma is that alongside the new cta_group operand, it enables larger MMA shapes that span across 2-CTAs within a thread block cluster.
B200 Specifications
Developed on the TSMC 4NP process node, the B200 has the following specifications:
- Power Target: 1000W
- Maximum Clock Speed: 1.965 GHz
- Base Clock Speed: 700 MHz
- Streaming Multiprocessor Count: 148
- L2 Cache: 126 MB
- Die Arrangement: 2 Dies
- VRAM: 288 GB HBM3E @ 8 TB/s
- Shared Memory per SM: 227 KB
Initial Kernel
We will now walk through iteratively optimizing a matrix multiplication kernel starting with the initial kernel that leverages the 2 main workhorses of NVIDIA GPUs, the Tensor Memory Accelerator (TMA) and Tensor Cores. The basic design of a CUDA matmul is to bring data from global memory (HBM) into shared memory, with its lower latency accesses, and then perform a matrix multiply accumulate on that data with Tensor Cores.
We will iterate using tiles of dimensions BMxBK for A and BKxBN for B along the K dimension. Where at each point we will perform a load using the TMA of a BMxBK tile of A and a BKxBN tile of B into smem. Then we will issue an MMA to compute the output tile from the A and B tiles. Both TMA and MMA are only issued by one thread, so we will choose an arbitrary warp, warp0, and elect one thread from it for both the TMA and MMA issues. Once our entire tile over K loop is finished, we can then write out output BMxBN tile back to C in HBM. Both TMA loads and MMA instructions are asynchronous, meaning that they work in the background and return control back to the issuing thread before the operation has completed. Given the asynchronous nature of TMA and MMA, we will use mbarriers to track and wait for their completion. This is needed on the TMA side as we need to ensure that smem is fully populated with A and B tiles in order for our MMA to have the operands it needs, and it is needed on the MMA side as we need to ensure that our MMA is fully completed with using the A and B tiles in smem, before we can load new A and B tiles into smem. In the TMA loads, we need an mbarrier expect/wait for (BM + BN) * BK * 2 bytes to arrive in order to signify that our TMA load has successfully moved both A and B tiles into smem. For synchronizing the MMA, after completing the loop over the BK dimension, we will perform a tcgen05_commit in order to link the execution of this MMA to our mbarrier, then we can wait for the MMA to finish.
// prologue: setting up tmem, allocating smem & tmem
for (int tile = 0; tile < K / BK; ++tile)
{
// tma load, only for elected thread
for (int k = 0; k < BK / 64; ++k)
{
const int col = iter_k * BK + k * 64;
const int offset_a = BM * k * 64 * sizeof(nv_bfloat16);
const int offset_b = BN * k * 64 * sizeof(nv_bfloat16);
tma_2d_gmem2smem(A_smem + offset_a, &A_tmap, col, blockIdx.y * BM, mbar_addr);
tma_2d_gmem2smem(B_smem + offset_b, &B_tmap, col, blockIdx.x * BN, mbar_addr);
}
mbarrier_arrive_expect(mbar_addr, (BM + BN) * BK * sizeof(nv_bfloat16));
// mma computation, only for elected thread
for (int k1 = 0; k1 < BK / 64; ++k1)
{
for (int k2 = 0; k2 < 64 / MMA_K; ++k2)
{
int enable_accum = (tile == 0 && k1 == 0 && k2 == 0) ? 0 : 1;
const int offset = k1 * BM * 64 * sizeof(nv_bfloat16) + k2 * MMA_K * sizeof(nv_bfloat16);
const uint64_t a_smem_desc = make_smem_desc(A_smem + offset);
const int b_offset = k1 * BN * 64 * sizeof(nv_bfloat16) + k2 * MMA_K * sizeof(nv_bfloat16);
const uint64_t b_smem_desc = make_smem_desc(B_smem + b_offset);
tcgen05_mma_bf16<1>(tmem_addr, a_smem_desc, b_smem_desc, i_desc, enable_accum);
}
}
tcgen05_commit(mbar_addr);
mbarrier_wait(mbar_addr, phase);
}
// epilogue write back tile to HBM, dealloc tmemAt this starting point we are reaching about 40% of cuBLAS's performance.
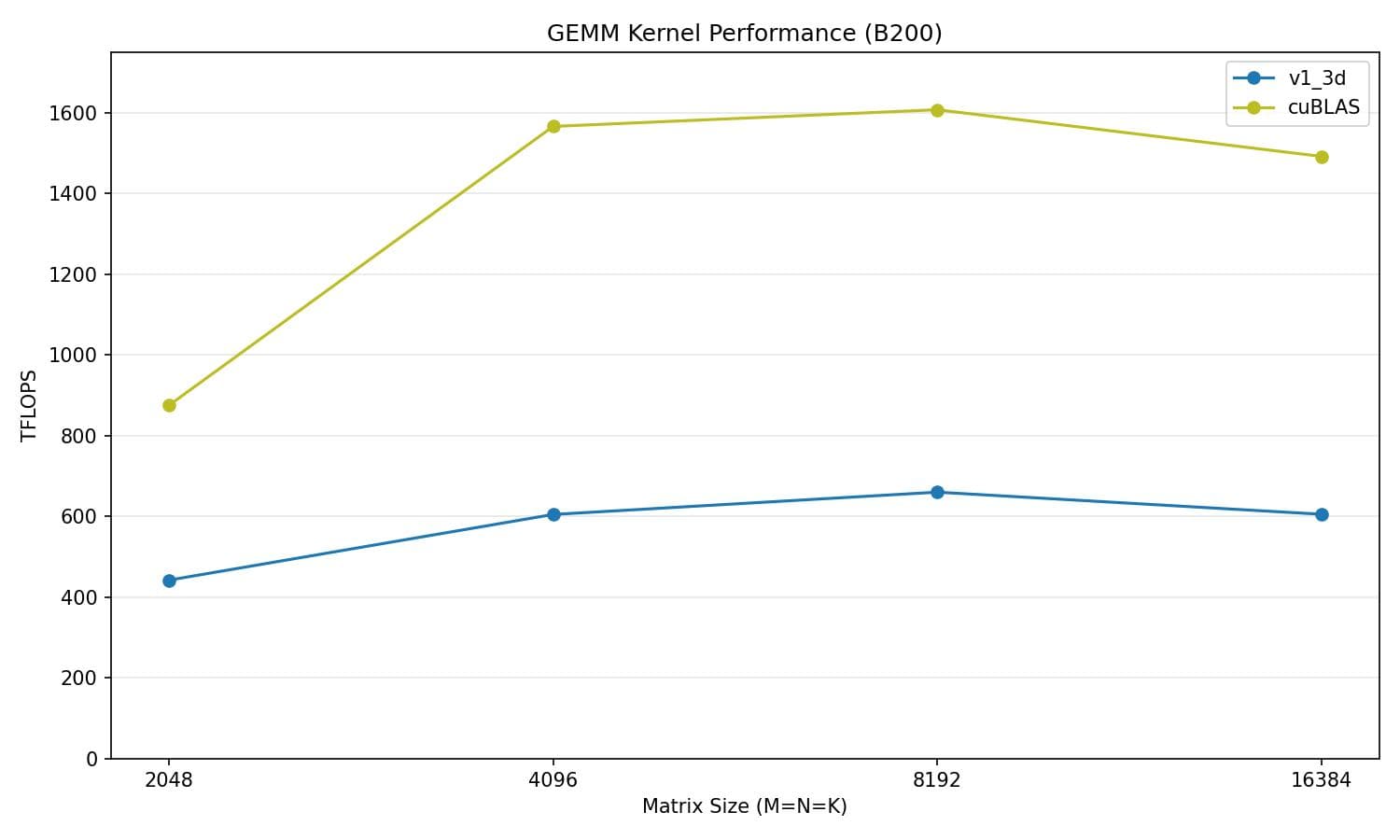
v1_3d vs cuBLAS
| Matrix size | v1_3d (TFLOPS) | cuBLAS (TFLOPS) | % of cuBLAS |
|---|---|---|---|
| 2048 | 441.9 | 838.9 | 52.7% |
| 4096 | 603.9 | 1520.5 | 39.7% |
| 8192 | 651.6 | 1551.0 | 42.0% |
| 16384 | 596.6 | 1424.8 | 41.9% |
2-CTA MMA
Our first optimization is to leverage 2-CTA MMA. 2-CTA MMA provides the ability for a pair of CTAs in the same thread block cluster to work together to produce 2 output tiles of C in one MMA instruction.
The benefit is that we can create a larger MMA tile, which in turn means that we can increase the arithmetic intensity of our operations. Arithmetic intensity is number of FLOPs / number of byte accesses. As tensor core performance grows faster than memory bandwidth, it is critical to get the most operations out of any operands fetched. Instead of doing 2 128x256 MMAs to get a 256x256 output tile, we can directly do 1 256x256 MMA to get the same result. For our purposes we will have each CTA contain a unique row of A and half of the shared column of B, with half of the 256x256 output tile being accumulated in the tmem of each CTA.
By having each CTA load half of B, we are saving a redundant load of B that occurs in 1-CTA MMA where the exact same column of B is loaded into the SMEM of both CTAs. The 1.5x arithmetic intensity benefit can be seen below:
In terms of actually implementing this optimization, we must first understand thread block clusters.
First introduced in Hopper, thread block clusters are a new level of hierarchy above CTAs. Clusters ensure that CTAs within a cluster are scheduled onto the same GPU Processing Cluster which guarantees that they will be on neighbouring SMs. The benefit of clusters is in being able to leverage Distributed Shared Memory, where CTAs are able to read from and write to the shared memory of other CTAs within the same cluster. So with thread block clusters we can store half of our B column across 2 CTAs while B is still accessible, which prevents the need for any data overlap.
We can enable thread block clusters by adding the __cluster_dims__(x, y, z) compile-time kernel attribute to our kernel. Cluster dimensions are not modifiable after launching the kernel. In our case we only need 2 CTAs per cluster so we will launch with the cluster dimensions of (2, 1, 1).
template<int BM, int BN, int BK>
__global__ __cluster_dims__(2, 1, 1)
void gemm_2sm_mma(const nv_bfloat16 *A, const nv_bfloat16 *B, nv_bfloat16 *C, int M, int N, int K,
const __grid_constant__ CUtensorMap A_tmap, const __grid_constant__ CUtensorMap B_tmap)Then we find the rank of the CTA through the %cluster_ctaid.x special register which contains the CTA identifier or rank within a cluster, with only 2 CTAs in our cluster it will return either 0 or 1, and we will choose CTA0 as the leader. In terms of changes to our kernel, the core logic remains the same but we need to adjust synchronization and which mbarriers to use.
asm volatile("mov.u32 %0, %%cluster_ctaid.x;" : "=r"(rank));Now that we are operating at the cluster level, __syncthreads() is no longer sufficient as we need to synchronize prologue and tmem dealloc across CTAs, so we will use the cluster equivalent which is: barrier.cluster.arrive.release.aligned and barrier.cluster.wait.acquire.aligned. The only TMA change is that both CTAs will now arrive on CTA0's tma_mbar and only CTA0 will have to wait for smem to finish loading before proceeding. We accomplish this by using the mapa instruction to map the local shared memory address of tma_mbar_addr on CTA1 to the tma_mbar_addr on CTA0. On the MMA side we now issue our MMA and tcgen05 instructions with the argument cta_group = 2 which encodes that we are using 2-CTA MMA and we will have to tcgen05_commit with multicast in order for both mma_mbar in CTA0 and CTA1 to track its completion. The multicast instruction takes a cta_mask operand which specifies which CTAs participate, 0b11 selects both so we will pass that as our cta_mask.
// prologue mbar, smem, tmem setup remains the same besides tma_mbar will have arrival count == 2
asm volatile("barrier.cluster.arrive.release.aligned;\n" "barrier.cluster.wait.acquire.aligned;\n" ::: "memory");
int tma_mbar = tma_mbar_addr;
if (cta_rank == 1)
{
tma_mbar = map_smem_addr_to_cta_rank(tma_mbar_addr, 0);
}
// TMA logic changes
if (warp_id == 0 && elect_sync())
{
constexpr int copy_size = (BM + BN / CTA_GROUP_SIZE) * BK * sizeof(nv_bfloat16);
mbarrier_arrive_expect_cluster(tma_mbar, copy_size);
int a_row = block_row * BM;
int b_row = block_col * BN + cta_rank * (BN / CTA_GROUP_SIZE);
tma_3d_gmem2smem<2>(A_smem, &A_tmap, 0, a_row, iter_k * BK / SWIZZLE_WIDTH, tma_mbar);
tma_3d_gmem2smem<2>(B_smem, &B_tmap, 0, b_row, iter_k * BK / SWIZZLE_WIDTH, tma_mbar);
}
// Only CTA 0 waits for both loads, as CTA1 will not issue an MMA
if (cta_rank == 0)
{
mbarrier_wait(tma_mbar_addr, tma_phase);
tcgen05_sync();
tma_phase ^= 1;
}
// MMA logic changes
if (cta_rank == 0 && warp_id == 0 && elect_sync())
{
for (int k1 = 0; k1 < BK / SWIZZLE_WIDTH; ++k1)
{
for (int k2 = 0; k2 < SWIZZLE_WIDTH / MMA_K; ++k2)
{
const int a_off = k1 * BM * SWIZZLE_WIDTH * sizeof(nv_bfloat16) + k2 * MMA_K * sizeof(nv_bfloat16);
const int b_off = k1 * (BN / CTA_GROUP_SIZE) * SWIZZLE_WIDTH * sizeof(nv_bfloat16) + k2 * MMA_K * sizeof(nv_bfloat16);
int enable = (iter_k == 0 && k1 == 0 && k2 == 0) ? 0 : 1;
uint64_t a_desc = make_smem_desc(A_smem + a_off);
uint64_t b_desc = make_smem_desc(B_smem + b_off);
tcgen05_mma_bf16<2>(tmem_addr, a_desc, b_desc, i_desc, enable);
}
}
tcgen05_commit_multicast(mma_mbar_addr, 0b11);
}
mbarrier_wait(mma_mbar_addr, mma_phase);
mma_phase ^= 1;
// Epilogue is the sameThis is a visual representation of how our new kernel executes.
We get a slight performance boost even with the arithmetic intensity increase as we have additional cluster-level synchronization. However the main benefit is that by decreasing the size of A and B tiles in smem, we can hold more A and B tiles in smem. Which leads us into our next optimization.
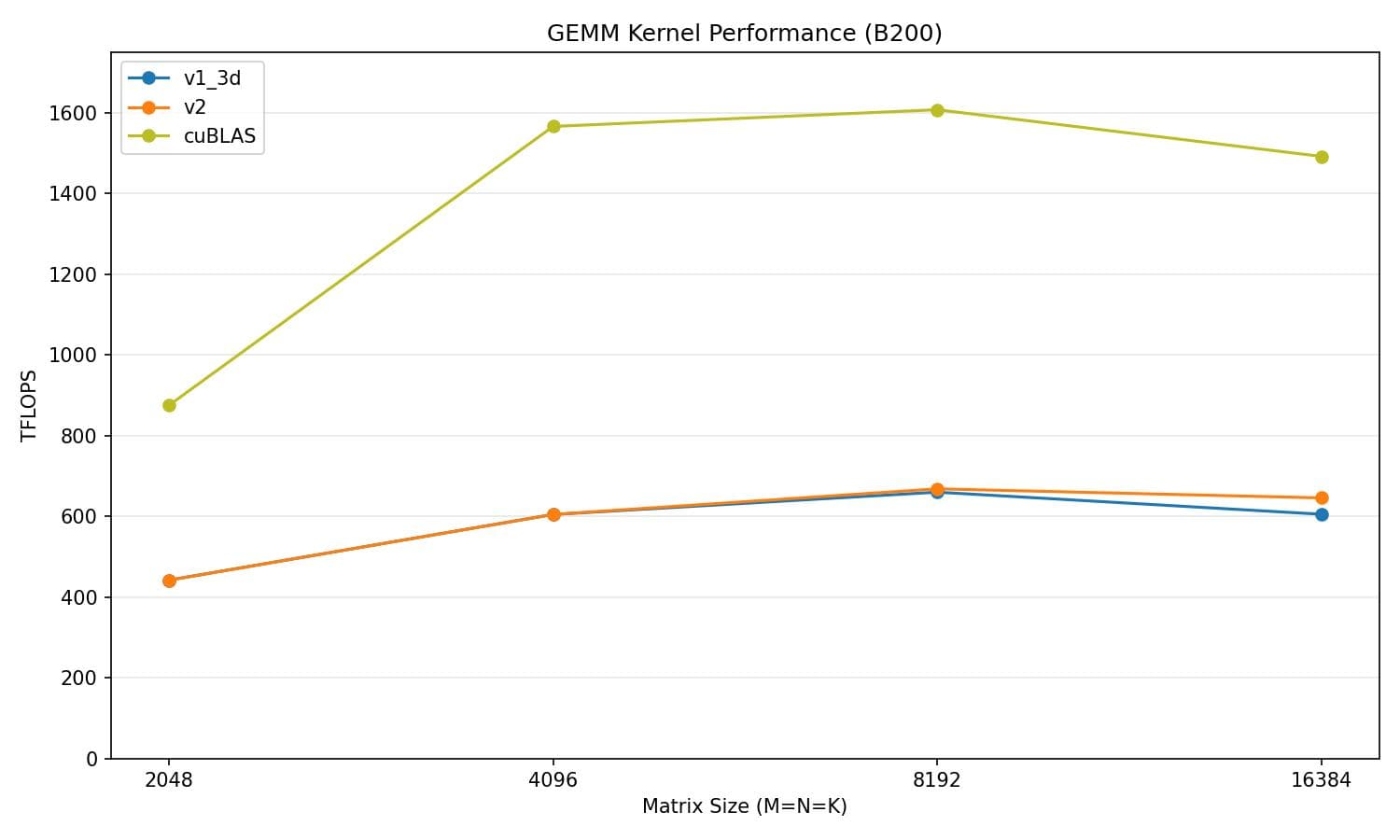
v2 vs cuBLAS
| Matrix size | v2 (TFLOPS) | cuBLAS (TFLOPS) | % of cuBLAS |
|---|---|---|---|
| 2048 | 441.5 | 838.9 | 52.6% |
| 4096 | 620.3 | 1520.5 | 40.8% |
| 8192 | 659.9 | 1551.0 | 42.5% |
| 16384 | 639.8 | 1424.8 | 44.9% |
Pipelining
In our previous approach execution was serialized, the kernel would either be waiting for a TMA load or waiting on an MMA, yet the TMA and tensor cores have the ability to run simultaneously. Both units are stalling waiting on each other because they are working on the same tile, but if they could work on different tiles, then we could eliminate these stalls almost entirely. We can first leverage this by pipelining or pre-loading tiles of A and B into smem with the TMA then run our normal loop of TMA load then MMA. The difference being that we would be loading tile i + 3 while doing MMA on tile i that was already preloaded into smem.
In terms of implementation we change our monolithic K / BK loop to first load our pipeline_depth tiles of A and B into smem. We then have our normal loop where we iterate over K, MMA remains the same but our TMA loads are now offset. As we preloaded tiles with TMA loads, we are left with tiles of A and B in smem that have yet to be consumed so we have our final loop to consume all tiles left in smem.
// prefetch
for (int i = 0; i < PIPELINE_DEPTH - 1; ++i)
{
load(i);
}
// main loop
for (int iter_k = 0; iter_k < num_iters - PIPELINE_DEPTH + 1; ++iter_k)
{
load(iter_k + PIPELINE_DEPTH - 1);
compute(iter_k);
mbarrier_wait(mma_mbar_addr, mma_phase);
mma_phase ^= 1;
}
// drain
for (int iter_k = num_iters - PIPELINE_DEPTH + 1; iter_k < num_iters; ++iter_k)
{
compute(iter_k);
mbarrier_wait(mma_mbar_addr, mma_phase);
mma_phase ^= 1;
}Now we are reaching about 70% of cuBLAS's performance.
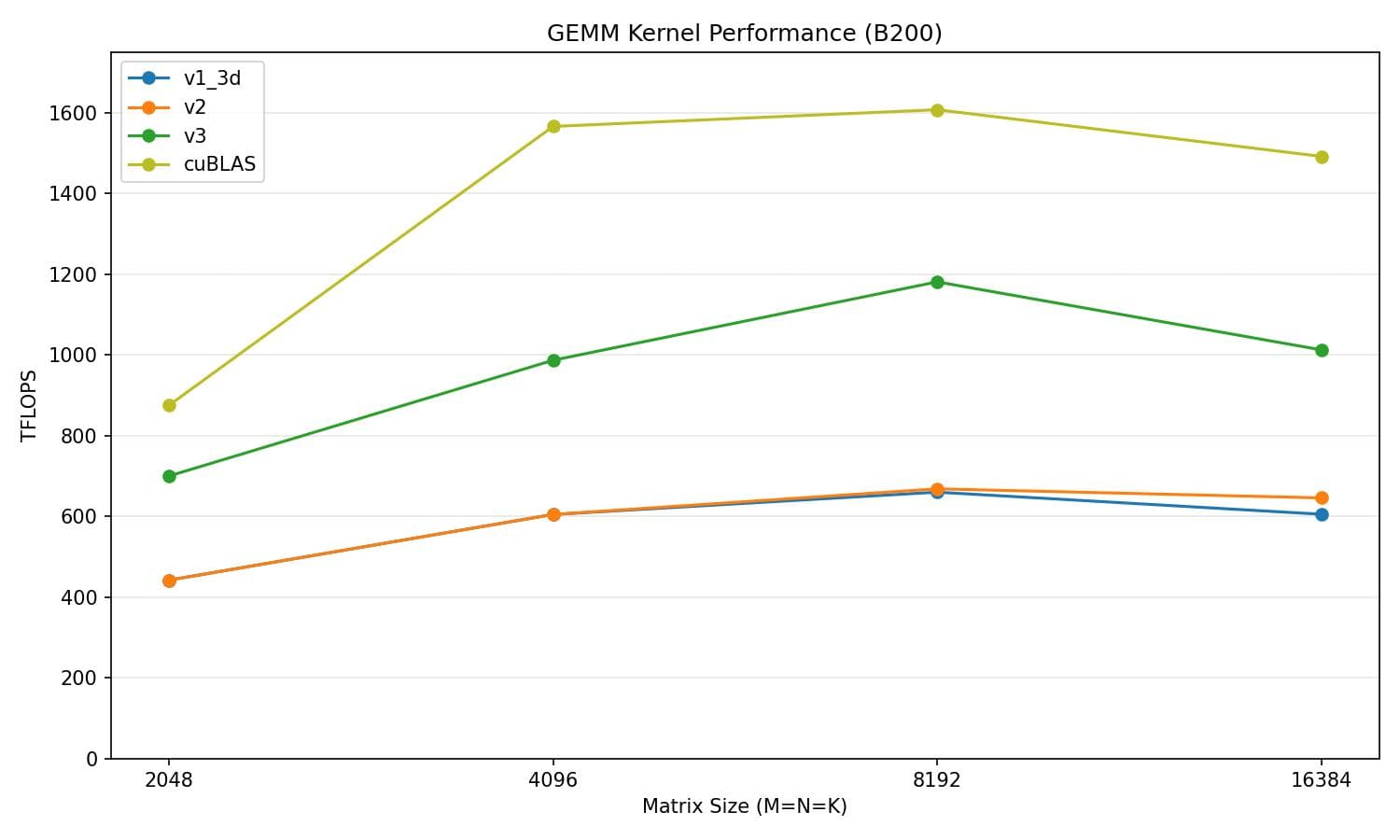
v3 vs cuBLAS
| Matrix size | v3 (TFLOPS) | cuBLAS (TFLOPS) | % of cuBLAS |
|---|---|---|---|
| 2048 | 646.1 | 838.9 | 77.0% |
| 4096 | 971.9 | 1520.5 | 63.9% |
| 8192 | 1070.6 | 1551.0 | 69.0% |
| 16384 | 911.5 | 1424.8 | 64.0% |
Warp Specialization
As only 1 thread of 1 warp is needed to issue a TMA load or MMA instruction we can create dedicated warps that either only issue TMA loads (producers) or only issue MMAs (consumers). Since TMA loads and tensor core MMAs execute asynchronously, they will only be constrained by the state of the current tile.
In order to maximally minimize stall times, we need to maximize the amount of tiles that we can store in smem. Each SM has 227 KB of smem, so total tiles stored in smem is simply 227 KB / (A_tile_size + B_tile_size). However, the default maximum smem size for a CTA is 48 KB, so we will use cudaFuncSetAttribute on the host side to set the MaxDynamicSharedMemorySize to our required smem.
constexpr int tile_size = (BM + BN / CTA_GROUP_SIZE) * BK * sizeof(nv_bfloat16);
constexpr int QUEUE_SIZE = 227 * 1024 / tile_size;
constexpr int smem_size = tile_size * QUEUE_SIZE;
cudaFuncSetAttribute(warp_specialized_gemm<BM, BN, BK, QUEUE_SIZE>, cudaFuncAttributeMaxDynamicSharedMemorySize, smem_size);On the device side, in order to manage the state of the smem buffers we will have a queue_size number of full_mbar and empty_mbar mbarriers. Each mbar will track the state of a tile (empty or full). We also need one mbarrier to denote when the last consumer has finished so that the epilogue can begin.
__shared__ __align__(8) uint64_t full_mbar_storage[QUEUE_SIZE];
__shared__ __align__(8) uint64_t empty_mbar_storage[QUEUE_SIZE];
__shared__ __align__(8) uint64_t consumers_finished[1];We can assign any arbitrary warp to be a producer/consumer and we can reuse these warps for our epilogue warpgroup, so we only need 4 warps. On the kernel side we will change which mbar our producer and consumer will wait on and arrive/commit on.
- Producer: Waits on empty_mbar of the current tile, arrives on full_mbar of the current tile.
- Consumer: Waits on full_mbar of the current tile, arrives on empty_mbar of the current tile.
if (warp_id == producer_warp_id && elect_sync()) // load
{
for (int iter_k = 0; iter_k < num_k; advance_stage(iter_k))
{
if (iter_k >= QUEUE_SIZE)
{
mbarrier_wait(empty_mbar_addr + stage_idx * 8, phase ^ 1);
}
// calc a, b smem, and mbars for curr iter
int A_smem_s = smem_ptr + stage_idx * copy_size;
int B_smem_s = A_smem_s + BM * BK * sizeof(nv_bfloat16);
int A_row = block_row * BM;
int B_row = block_col * BN + cta_rank * (BN / CTA_GROUP_SIZE);
int local_full_mbar = tma_mbar + stage_idx * 8;
mbarrier_arrive_expect_cluster(local_full_mbar, copy_size);
tma_3d_gmem2smem<CTA_GROUP_SIZE>(A_smem_s, &A_tmap, 0, A_row, iter_k * BK / SWIZZLE_WIDTH, local_full_mbar);
tma_3d_gmem2smem<CTA_GROUP_SIZE>(B_smem_s, &B_tmap, 0, B_row, iter_k * BK / SWIZZLE_WIDTH, local_full_mbar);
}
}On the producer side we need to adjust our TMA loads for the current tile that we are on which is based on the current buffer or stage. We will also have to wait for our current tile to be empty, which is signaled by the empty_mbar_addr mbarrier. For the first queue_size iterations we don't have to wait as the tiles are default empty when we launch the kernel. On completion of the TMA load the producer will arrive on the full_mbar which signals that the current tile is full and ready for any consumer.
else if (cta_rank == 0 && warp_id == consumer_warp_id && elect_sync()) // compute
{
for (int iter_k = 0; iter_k < num_k; advance_stage(iter_k))
{
int current_full_mbar = full_mbar_addr + stage_idx * 8;
int current_empty_mbar = empty_mbar_addr + stage_idx * 8;
mbarrier_wait(current_full_mbar, phase);
asm volatile("tcgen05.fence::after_thread_sync;");
int A_smem_s = smem_ptr + stage_idx * copy_size;
int B_smem_s = A_smem_s + BM * BK * sizeof(nv_bfloat16);
for (int k1 = 0; k1 < BK / SWIZZLE_WIDTH; ++k1)
{
for (int k2 = 0; k2 < SWIZZLE_WIDTH / MMA_K; ++k2)
{
const int enable_accum = (iter_k == 0 && k1 == 0 && k2 == 0) ? 0 : 1;
const int a_offset = k1 * SWIZZLE_WIDTH * BM * sizeof(nv_bfloat16) + k2 * MMA_K * sizeof(nv_bfloat16);
const int b_offset = k1 * SWIZZLE_WIDTH * (BN / CTA_GROUP_SIZE) * sizeof(nv_bfloat16) + k2 * MMA_K * sizeof(nv_bfloat16);
uint64_t a_desc = make_smem_desc(A_smem_s + a_offset);
uint64_t b_desc = make_smem_desc(B_smem_s + b_offset);
tcgen05_mma_bf16<CTA_GROUP_SIZE>(tmem_addr, a_desc, b_desc, i_desc, enable_accum);
}
}
tcgen05_commit_multicast<CTA_GROUP_SIZE>(current_empty_mbar, cta_mask);
} The consumer has the same adjustment for the current tile/stage but will wait on mbar_full and commit to mbar_empty once it has consumed the tile.
Now we are reaching about 82.8% of cuBLAS's performance on average, a 14.3-point gain over v3.
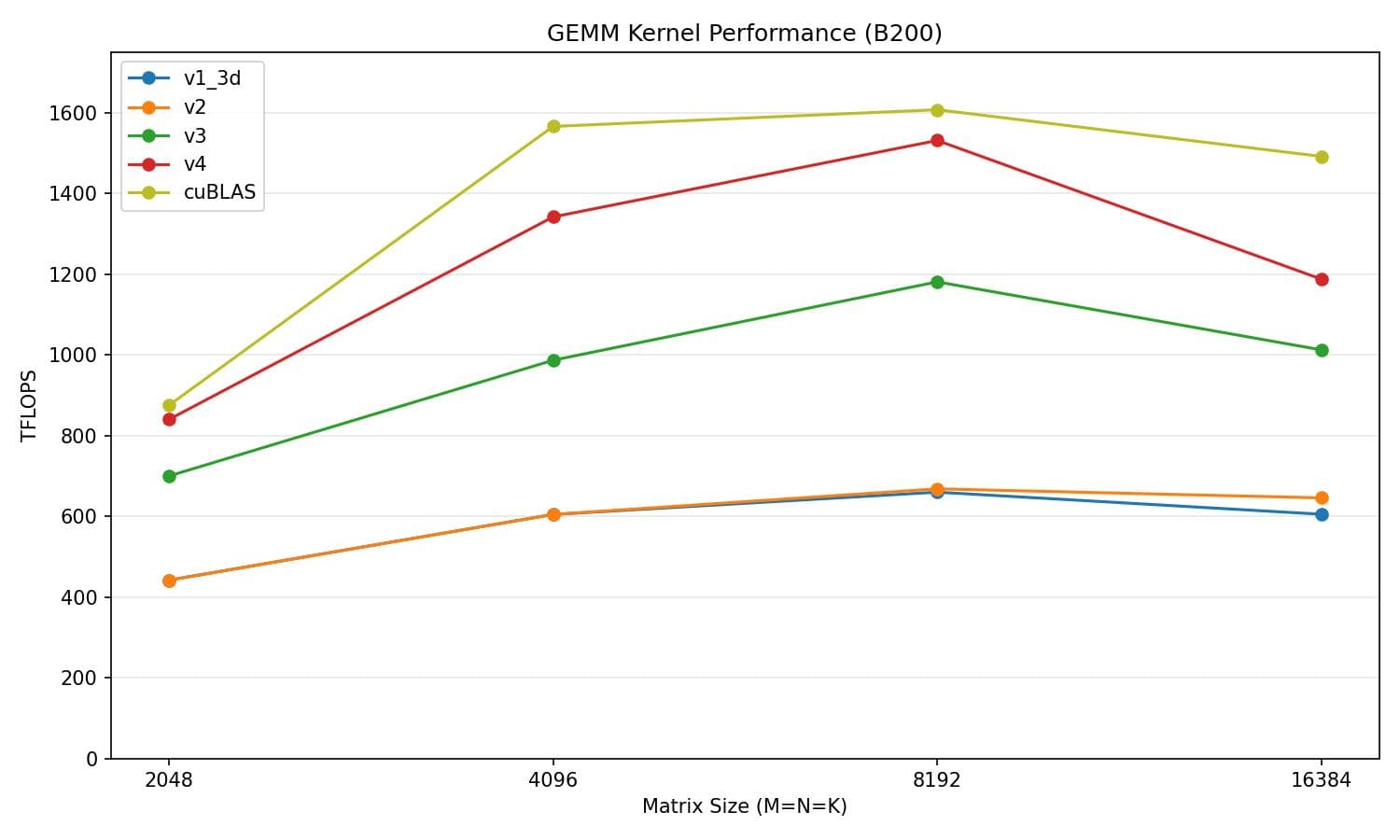
v4 vs cuBLAS
| Matrix size | v4 (TFLOPS) | cuBLAS (TFLOPS) | % of cuBLAS |
|---|---|---|---|
| 2048 | 762.6 | 838.9 | 90.9% |
| 4096 | 1290.9 | 1520.5 | 84.9% |
| 8192 | 1242.7 | 1551.0 | 80.1% |
| 16384 | 1073.3 | 1424.8 | 75.3% |
Persistent Kernel
The execution of our warp-specialized kernel looks like this. (note that each block represents time not number of TMA loads/MMA instructions issued and that the actual issue/wait is not synced this is just shown for brevity).
Throughout the execution of the kernel we can see that the producer and consumer are issuing TMA loads and MMA instructions, except for during the epilogue phase. During the epilogue, both the producer and consumer can only wait as there is no data to load or compute on, which means that our TMA and tensor cores are completely idle.
The solution to this problem is a persistent kernel. Instead of launching 1 kernel for each BMxBN output tile in C, we can have each kernel produce total_output_tiles / total_kernels_launched tiles. Each kernel will have a new outer-loop that assigns the next output tile to work on. So when the kernel reaches the epilogue stage, the epilogue warpgroup can begin the epilogue for output tile i, while the producer can begin loading tiles for output tile i + 1. With this approach our new execution will look like this:
The 2 main benefits are that:
- The prologue costs (smem/tmem allocation, mbarrier initialization) and kernel launch overhead are paid once across the 148 kernels launched, rather than once per output tile.
- The TMA can begin loading A and B tiles into smem for the next output tile during the epilogue of the current output tile keeping the TMA busy.
However, we currently cannot issue any MMA instructions during the epilogue as the tmem buffer is still being used for the epilogue. Which brings us to our next optimization that is needed to fully overlap our main loop with the epilogue.
Double-Buffering Tensor Memory
As we have previously noted, tmem consists of 128 lanes and 512 columns. Given that our BM value is 128 and BN is 256, we can store 2 output tiles/buffers in tmem. With this approach we can have 2 128x256 tiles in flight, with each tile either in the epilogue state or in the mainloop/MMA accumulation state.
Now when the kernel reaches the epilogue stage, tensor cores can work on the next tile by accumulating in the other empty tmem buffer. Our new execution looks like this:
In terms of implementing this into our kernel, we first have to change the number of kernels that we launch. Instead of launching (M / BM) * (N / BN) kernels we will instead launch as many kernels as SMs, which on the B200 is 148.
dim3 grid(SM_COUNT);
kernel<<<grid, block_size, smem_size>>>(A, B, C, M, N, K, A_tmap, B_tmap, C_tmap, profiler_ptr, num_entries);Inside the kernel we have to add an additional loop, with the producer and consumer operating as the inner loop over K and the new outer loop iterating over output tiles. Each CTA will grab a tile, then run the full main loop with the output tile accumulated into tmem, signals the epilogue, then immediately starts a new main loop with the next tile.
if (warp_id == producer_warp_id && elect_sync())
{
while (get_next_tile())
{
for (int iter_k = 0; iter_k < k_iters; advance_stage(iter_k))
{
// producer logic
}
}
}
if (cta_rank == 0 && warp_id == consumer_warp_id && elect_sync())
{
while (get_next_tile())
{
for (int iter_k = 0; iter_k < k_iters; advance_stage(iter_k))
{
// consumer logic
}
}
}
Next in order to coordinate the main loop and outer loop handoff, we need a second set of mbarriers which are tmem_full and tmem_empty. We will have one of each per epilogue stage, which in our case is 2. The consumer signals tmem_full after committing the last MMA of a tile, the epilogue waits on it before reading, and then signals tmem_empty once tmem reads are complete so that the consumer can reuse that buffer for accumulation of the next tile.
__shared__ __align__(8) uint64_t tmem_full[NUM_EPILOGUE_STAGES];
__shared__ __align__(8) uint64_t tmem_empty[NUM_EPILOGUE_STAGES];
// Consumer:
if (wave_iter >= NUM_EPILOGUE_STAGES)
{
mbarrier_wait(tmem_empty_addr + wave_stage * 8, wave_phase ^ 1);
}
// MMA logic
tcgen05_commit_multicast<CTA_GROUP_SIZE>(tmem_full_addr + wave_stage * 8, cta_mask);
// Epilogue:
mbarrier_wait(tmem_full_addr + wave_stage * 8, wave_phase);
// Epilogue logic
mbarrier_arrive_cluster(tmem_empty_cta0);The last piece is the scheduler itself, which is just a counter. Each cluster advances a local wave iterator, multiplies by the number of clusters in flight, and adds its cluster ID to get a globally unique tile index. Converting that flat index back into (block_row, block_col) is a single div-mod, and we terminate once the index runs past the total tile count. Every cluster independently computes which tiles belong to it, so there are no atomics or cross-cluster coordination needed.
auto get_next_tile = [&]()
{
int tile_idx = (++wave_iter) * num_clusters + cluster_id;
if (tile_idx >= total_tiles) return false;
block_col = tile_idx % grid_n;
block_row = (tile_idx / grid_n) * CTA_GROUP_SIZE + cta_rank;
return true;
};Now we are reaching about 88.2% of cuBLAS's performance on average, a 5.4-point gain over v4.
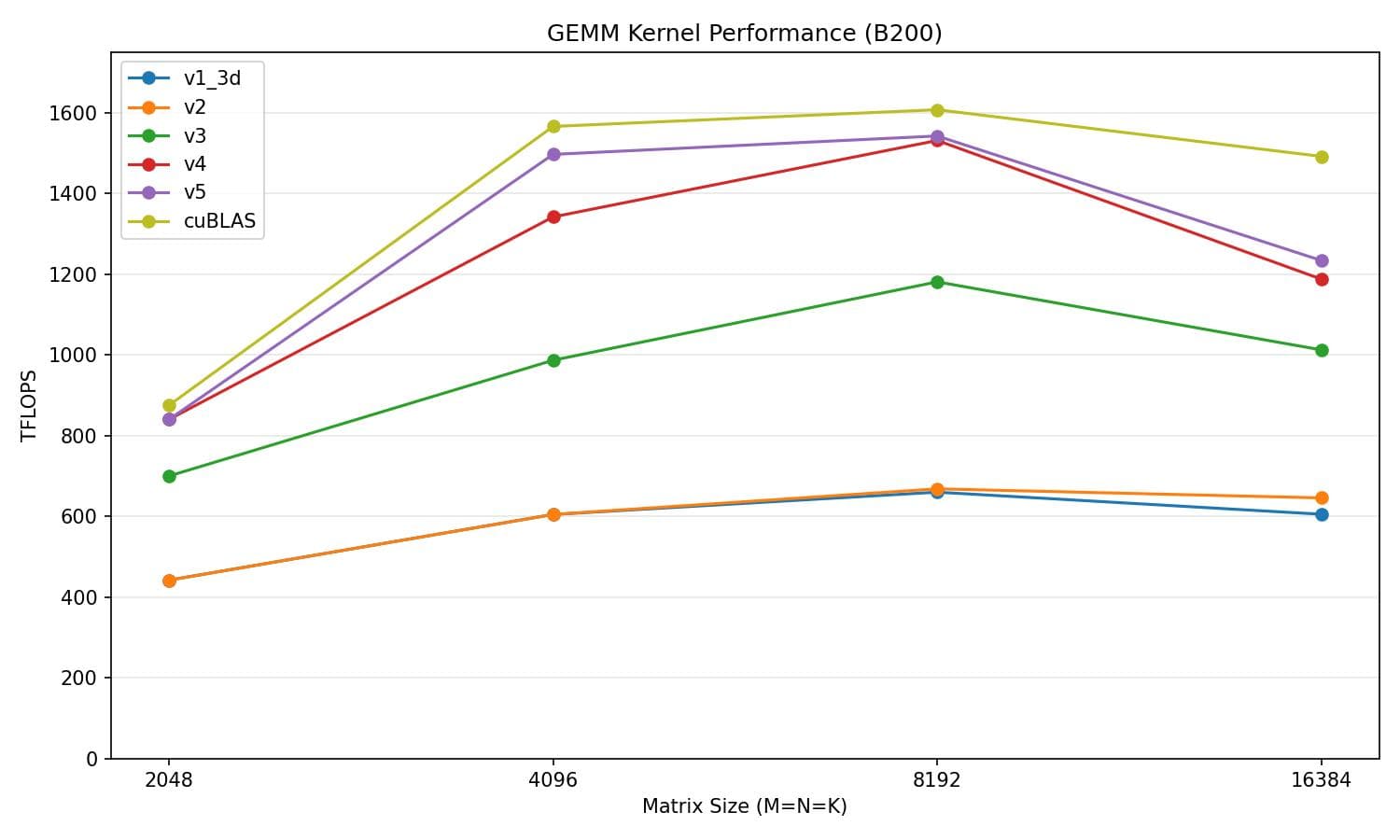
v5 vs cuBLAS
| Matrix size | v5 (TFLOPS) | cuBLAS (TFLOPS) | % of cuBLAS |
|---|---|---|---|
| 2048 | 762.6 | 838.9 | 90.9% |
| 4096 | 1473.3 | 1520.5 | 96.9% |
| 8192 | 1353.9 | 1551.0 | 87.3% |
| 16384 | 1106.1 | 1424.8 | 77.6% |
Epilogue Optimizations
Currently our epilogue writes from registers directly to HBM. The issue, along with these writes being uncoalesced, is that these loads utilize the Load/Store Unit (LSUs) which has finite throughput. Since throughput is limited, the LSU ends up stalling waiting to issue the next store. We can bypass this issue by using the TMA, which is a separate hardware unit that does not utilize the LSU. By routing our stores through TMA loads, we can sidestep this LSU bottleneck. As the TMA cannot read from registers, we must change our epilogue data path from tmem -> registers -> HBM to tmem -> registers -> smem -> HBM. However, naively staging the entire BMxBN tile in smem would cost multiple pipeline stages given the smem footprint. The solution is to pipeline the approach by breaking the output tile into chunks and executing the 3 stage process iteratively.
To avoid stalling between chunks, we can double buffer the smem staging area. While the TMA drains buffer n to HBM, the epilogue warps can then write the n + 1 chunk into buffer n + 1, which will keep the TMA hot.
Tensor Memory to Registers
Instead of issuing and waiting on each load individually, we can batch all initial tmem loads then wait with a single tcgen05.wait. Each load is independent so this batching avoids unnecessary serialization. Also once all of the values are loaded from tmem to registers, this tmem buffer is now empty so we can signal to any waiting consumer warp that it can freely write to this buffer.
if (warp_id == 0) tma_store_wait<NUM_TMA_STORE_STAGES - 1>(); float tmp[LOADS_PER_CHUNK][8]; #pragma unroll for (int n = 0; n < LOADS_PER_CHUNK; ++n) { tcgen05_ld(tmp[n], tmem_row + chunk * STORE_N + n * 8); } tcgen05_wait_ld(); if (chunk == num_chunks - 1) { tcgen05_before_thread_sync(); const int tmem_empty_cta0 = (tmem_empty_addr + wave_stage * 8) & 0xFEFFFFFF; if (elect_sync()) { mbarrier_arrive_cluster(tmem_empty_cta0); } } barrier_sync(EPILOGUE_BAR, EPILOGUE_THREADS);Registers to Shared Memory
#pragma unroll for (int n = 0; n < LOADS_PER_CHUNK; ++n) { nv_bfloat162 packed_bf[4]; #pragma unroll for (int i = 0; i < 4; ++i) { packed_bf[i] = __float22bfloat162_rn({tmp[n][i * 2], tmp[n][i * 2 + 1]}); } const int swizzled_n = n ^ (row & 7); nv_bfloat16 *write_ptr = store_base + store_stage * BM * STORE_N + row * STORE_N + swizzled_n * 8; *reinterpret_cast<int4*>(write_ptr) = *reinterpret_cast<int4*>(packed_bf); } __syncwarp(); tma_store_fence(); barrier_sync(EPILOGUE_BAR, EPILOGUE_THREADS);Shared Memory to HBM
Finally, we can have 1 thread per warpgroup issue the TMA load of the output to HBM.
if (warp_id == 0 && elect_sync()) { const int src = store_smem + store_stage * store_buf_size; tma_2d_smem2gmem(src, &C_tmap, block_col * BN + chunk * STORE_N, block_row * BM); tma_store_commit(); } store_stage ^= 1;
Now we are reaching about 88.9% of cuBLAS's performance on average, a 0.7-point gain over v5.
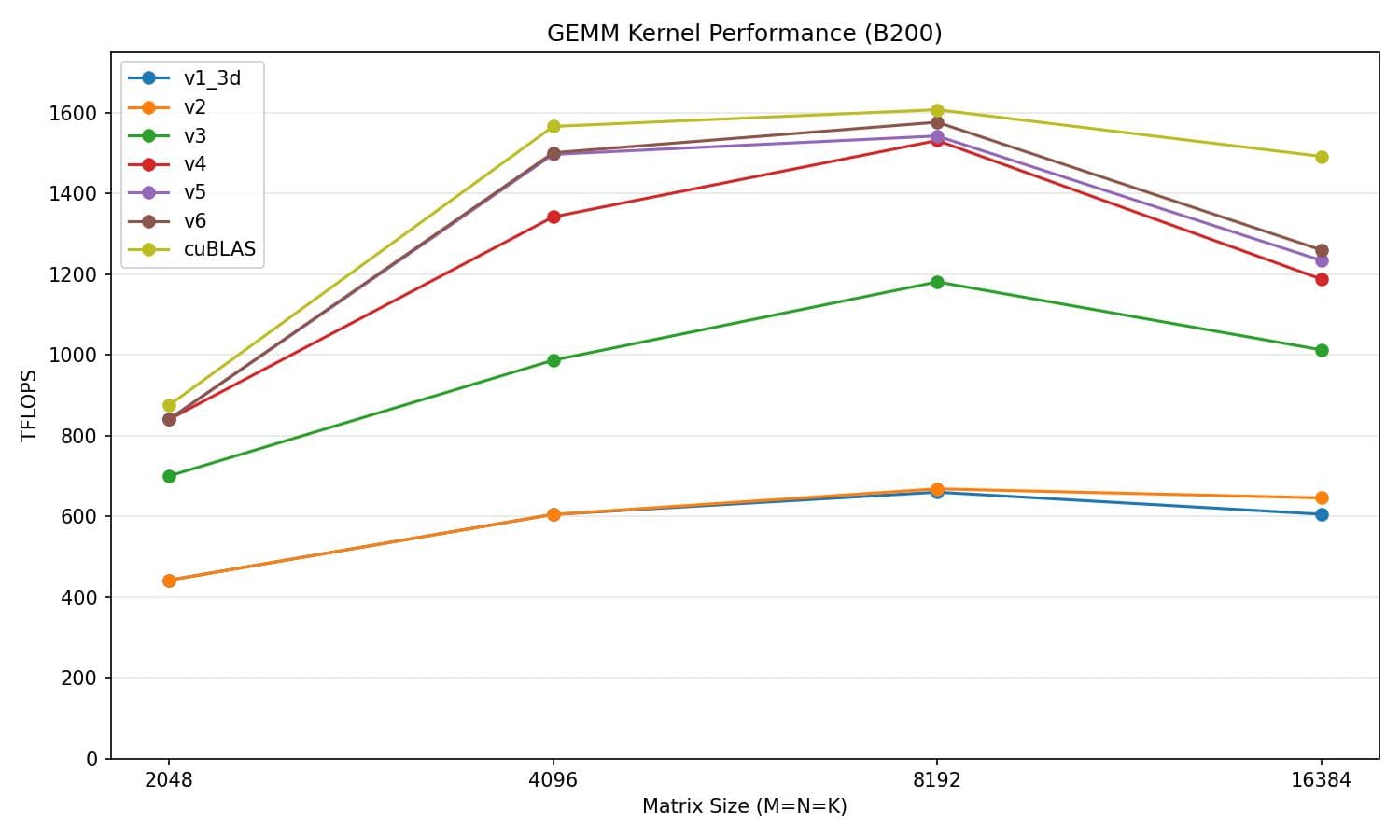
v6 vs cuBLAS
| Matrix size | v6 (TFLOPS) | cuBLAS (TFLOPS) | % of cuBLAS |
|---|---|---|---|
| 2048 | 762.6 | 838.9 | 90.9% |
| 4096 | 1490.8 | 1520.5 | 98.0% |
| 8192 | 1362.7 | 1551.0 | 87.9% |
| 16384 | 1121.6 | 1424.8 | 78.7% |
Hilbert Curves
Our persistent scheduler assigns tiles by striding each cluster's index by 74 (the total number of clusters) . This means each cluster jumps across the output grid with a stride that's large enough to evict the A and B tiles it just loaded before it can reuse them. As A and B tiles used by output tile i are likely not being used for output tile i + 74. We can see the impact by profiling our kernel with M=N=K=8192 using Nsight Compute:
Memory Workload Analysis
| Memory Throughput [Tbyte/s] | 2.67 | Mem Busy [%] | 48.45 |
| L1/TEX Hit Rate [%] | 78.21 | Max Bandwidth [%] | 51.48 |
| L2 Hit Rate [%] | 49.23 | Mem Pipes Busy [%] | 89.39 |
With a 49.23% L2 hit rate about half of our requests are going straight to HBM instead of from cache. We can solve this by adjusting our tile traversal to make consecutive tiles in each cluster's schedule, also be spatially close in the output grid. This way A and B blocks can stay resident in L2 cache. Hilbert curves solve exactly this problem. A Hilbert curve maps 1D indices to 2D coordinates while maintaining spatial locality. Specifically it guarantees that consecutive blocks will always have a Manhattan distance of exactly 1. Meaning that the next tile will always be in the same row, same column, or diagonally adjacent to the current tile. Here is a Hilbert curve traversing a grid:
The Hilbert curve algorithm is standard so we won't go into it, but we will take a look at the scheduler. To integrate this into our kernel we first have to precompute the full tile schedule on host and then upload it to a buffer in HBM so that each cluster can retrieve its indexes without any computation.
Since Hilbert curves require a power of 2 grid, we have to round up to the smallest power of 2 that covers both dimensions. We then walk every index along the curve, convert it into 2D coordinates, and skip any that are outside of the grid. As we walk we will pack valid tiles into a single int value with the row value being in the upper 16 bits and the column value being in the lower 16 bits.
// Precompute Hilbert-ordered tile assignments on host (cached across calls)
const int grid_m = M / BM / CTA_GROUP_SIZE;
const int grid_n = N / BN;
const int total_tiles = grid_m * grid_n;
const int num_clusters = SM_COUNT / CTA_GROUP_SIZE;
const int max_tiles_per_cluster = (total_tiles + num_clusters - 1) / num_clusters;
static int* d_tile_order = nullptr;
static int cached_M = 0, cached_N = 0;
if (M != cached_M || N != cached_N)
{
int hilbert_n = 1;
while (hilbert_n < grid_m || hilbert_n < grid_n) hilbert_n <<= 1;
// Round-robin deal Hilbert-ordered tiles to clusters
int order_size = num_clusters * max_tiles_per_cluster;
std::vector<int> tile_order_host(order_size, -1);
std::vector<int> cluster_count(num_clusters, 0);
int cluster_idx = 0;
for (int d = 0; d < hilbert_n * hilbert_n; d++)
{
int hx, hy;
hilbert_d2xy_host(hilbert_n, d, hx, hy);
if (hx >= grid_n || hy >= grid_m) continue;
int packed = (hy << 16) | hx;
tile_order_host[cluster_idx * max_tiles_per_cluster + cluster_count[cluster_idx]] = packed;
cluster_count[cluster_idx]++;
cluster_idx = (cluster_idx + 1) % num_clusters;
}
if (d_tile_order) cudaFree(d_tile_order);
cudaMalloc(&d_tile_order, order_size * sizeof(int));
cudaMemcpy(d_tile_order, tile_order_host.data(), order_size * sizeof(int), cudaMemcpyHostToDevice);
cached_M = M;
cached_N = N;
}
On the device side, we update the scheduler to become a single gmem read that only reads packed coordinates instead of performing any computation. Each cluster indexes into its contiguous slice of the precomputed buffer and unpacks the coordinates of the tiles. Once there are no tiles left, the scheduler will return false and the kernel will stop executing.
auto get_next_tile = [&]()
{
++wave_iter;
if (wave_iter >= max_tiles_per_cluster) return false;
int packed = tile_order[cluster_id * max_tiles_per_cluster + wave_iter];
if (packed == -1) return false;
block_col = packed & 0xFFFF;
block_row = (packed >> 16) * CTA_GROUP_SIZE + cta_rank;
return true;
};
With this change on host and to our scheduler, we are able to get a 15% increase in our L2 hit rate as illustrated by NCU:
Memory Workload Analysis
| Memory Throughput [Tbyte/s] | 1.68 | Mem Busy [%] | 40.42 |
| L1/TEX Hit Rate [%] | 79.35 | Max Bandwidth [%] | 51.08 |
| L2 Hit Rate [%] | 64.89 | Mem Pipes Busy [%] | 87.41 |
Now we are reaching about 91.9% of cuBLAS's performance on average, a 3.0-point gain over v6.
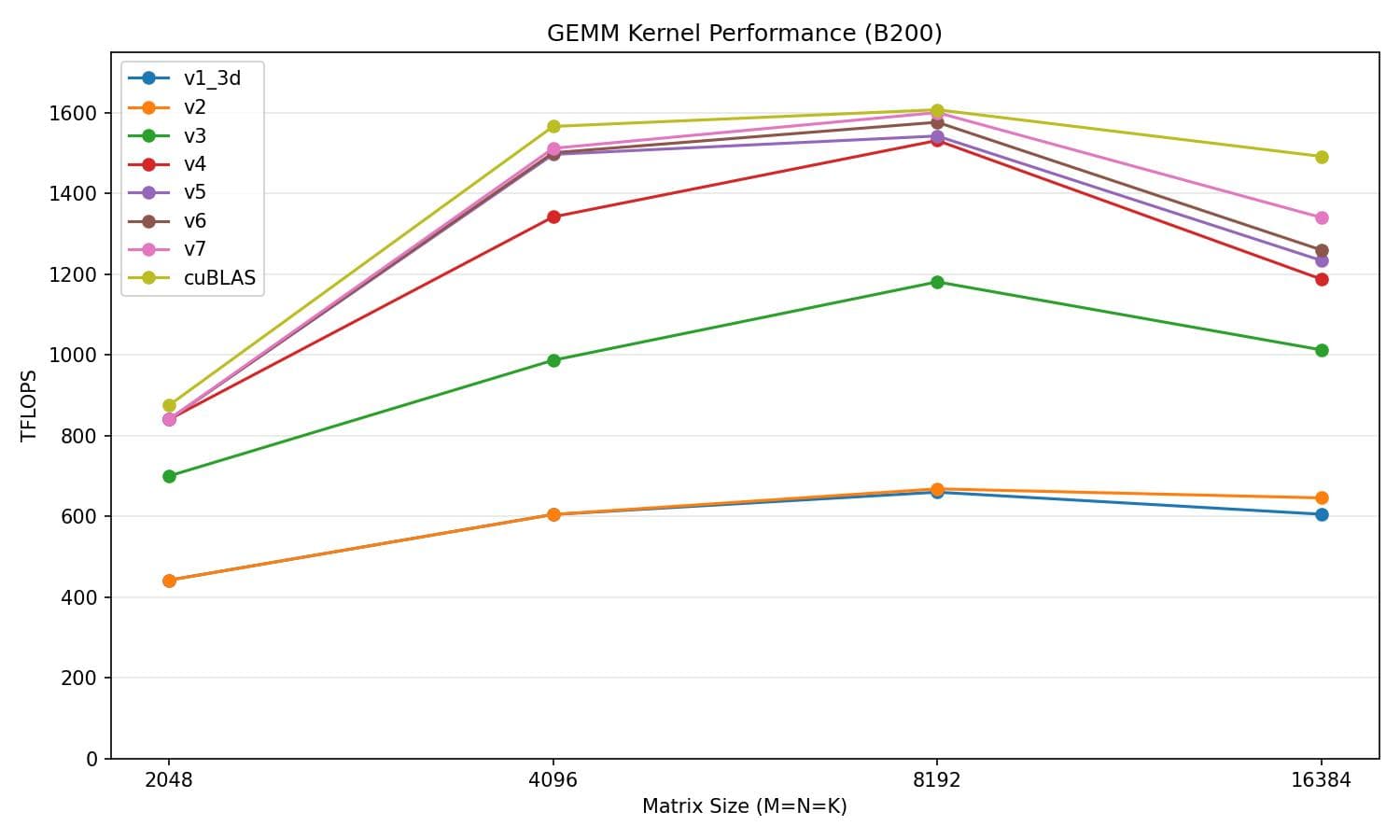
v7 vs cuBLAS
| Matrix size | v7 (TFLOPS) | cuBLAS (TFLOPS) | % of cuBLAS |
|---|---|---|---|
| 2048 | 762.6 | 838.9 | 90.9% |
| 4096 | 1494.3 | 1520.5 | 98.3% |
| 8192 | 1408.9 | 1551.0 | 90.8% |
| 16384 | 1245.1 | 1424.8 | 87.4% |
Cluster Launch Control
At M=N=K=16384 our current kernel's gap vs cuBLAS widens compared to smaller matrix dims. 2 issues are causing this. The first is the tail effect. As our output tiles are dispatched to SMs in waves, when our output tile count is not an exact multiple of SM count, our final wave will only partially saturate our SMs. This causes each SM, along with its TMA and tensor cores, to sit idle resulting in wasted computing capability. The second is runtime variance. Even SMs within the same full wave will finish executing at different times due to variables like L2 cache state and inter-die latency. With a static scheduler, the tile to SM assignment is fixed at launch so fast SMs have no way to process more tiles, which would effectively hide the latency caused by slower SMs. Cluster launch control fixes both by naturally load balancing across SMs. When an SM finishes a tile, it can claim the next output tile via CLC by getting its CTA id and mapping it to block_row and block_col. Tiles will flow to whichever SM is free first, so the partial tail wave can be grabbed by idle SMs rather than blocking to wait for slower SMs.
Cluster launch control can be accessed via 2 PTX instructions:
The first is try_cancel which atomically requests cancelling a cluster in the queue. It returns an opaque 16 byte response that indicates whether or not the request succeeded, where success will return the id of the first CTA in the cancelled cluster.
clusterlaunchcontrol.try_cancel.async{.space}.completion_mechanism{.multicast::cluster::all}
.b128 [addr], [mbar];
.completion_mechanism = { .mbarrier::complete_tx::bytes };
.space = { .shared::cta };| Argument | Description |
|---|---|
| addr | Naturally aligned address of a 16 byte smem location where the opaque response is written. With multicast.cluster::all, the same offset in every CTA of the cluster receives a copy of the output. |
| mbar | Address of a shared memory mbarrier that tracks completion of the response. Must have expect_tx(16) set; hardware arrives on it via complete_tx::bytes when the 16-byte response lands. |
The second is query_cancel which handles processing the opaque response. It has 3 variants with the first instruction being query_cancel.is_canceled which sets a 1 bit register (predicate) to whether or not the cancellation query was successful. If the cancellation was successful, we can then use the query_cancel.get_first_ctaid to retrieve the CTA id of the first CTA in the cancelled cluster from the response. The .v4.b32.b128 form returns all 3 axes (x, y, z) at once into a 4 register vector. While the per-axis form {::x, ::y, or ::z} returns a single coordinate into 1 32-bit register. As our grid and cluster are both 1D, we will opt to just use the per-axis form and just get the x dimension.
clusterlaunchcontrol.query_cancel.is_canceled.pred.b128 pred, try_cancel_response;
clusterlaunchcontrol.query_cancel.get_first_ctaid.v4.b32.b128 {xdim, ydim, zdim, _}, try_cancel_response;
clusterlaunchcontrol.query_cancel.get_first_ctaid{::dimension}.b32.b128 reg, try_cancel_response;
::dimension = { ::x, ::y, ::z };| Argument | Description |
|---|---|
| try_cancel_response | 16 byte register holding the opaque response from try_cancel, loaded from smem via ld.shared.b128. |
To implement this into our kernel we will create a new scheduler warp to handle this CLC-based approach to tile scheduling. Here the scheduler warp will act as the producer of the response values (CTA id), and the consumer, producer, epilogue, and scheduler warps will all be consumers. The scheduler warp has to be both as reading the failure response is the only way that each warp will end its execution, so without it the scheduler warps would need another layer to serve the same purpose. To implement this we added 2 new mbars: clc_full_mbar which signals that a fresh try_cancel response has loaded into the 16-byte smem buffer, and clc_empty_mbar which signals that all consumers have finished reading the buffer so the scheduler can issue the next try_cancel. CTA0's scheduler will issue try_cancel as the .multicast::cluster::all modifier broadcasts the 16-byte response into each CTA's local smem buffer. This way each warp is able to read the response from its local CTA buffer instead of having to use mapa. Each warp will still arrive on only CTA0's clc_empty_mbar as only CTA0's scheduler will issue the try_cancel.
We can also hide the try_cancel issue latency by creating a pipeline of depth 2, so that the scheduler warp can always prefetch the next response. This way the consumer warps are never stalled waiting for the scheduler warp.
else if (warp_id == scheduler_warp_id && elect_sync())
{
// Issue NUM_CLC_STAGES (2) try_cancels so queries are in flight immediately
// The CLC query latency for stage S+1 overlaps with the consumer work for stage S's response
if (cta_rank == 0)
{
#pragma unroll
for (int s = 0; s < NUM_CLC_STAGES; ++s)
{
mbarrier_arrive_expect_cluster(clc_full_mbar_addr + s * 8, 16);
int remote_full = map_smem_addr_to_cta_rank(clc_full_mbar_addr + s * 8, 1);
mbarrier_arrive_expect_cluster(remote_full, 16);
clc_try_cancel(clc_response_addr + s * 16, clc_full_mbar_addr + s * 8);
}
}
int clc_stage = 0;
int clc_full_phase = 0;
int clc_empty_phase = 0;
while (true)
{
mbarrier_wait(clc_full_mbar_addr + clc_stage * 8, clc_full_phase);
uint32_t is_valid, new_ctaid;
clc_query_response(clc_response_addr + clc_stage * 16, is_valid, new_ctaid);
mbarrier_arrive_cluster(cta0_clc_empty_addr + clc_stage * 8);
int issue_stage = clc_stage;
clc_stage = (clc_stage + 1) % NUM_CLC_STAGES;
if (clc_stage == 0) clc_full_phase ^= 1;
if (!is_valid) break;
// Refill the slot we just consumed — its CLC response will be
// consumed NUM_CLC_STAGES iterations from now
if (cta_rank == 0)
{
mbarrier_wait(clc_empty_mbar_addr + issue_stage * 8, clc_empty_phase);
if (issue_stage == NUM_CLC_STAGES - 1) clc_empty_phase ^= 1;
mbarrier_arrive_expect_cluster(clc_full_mbar_addr + issue_stage * 8, 16);
int remote_full = map_smem_addr_to_cta_rank(clc_full_mbar_addr + issue_stage * 8, 1);
mbarrier_arrive_expect_cluster(remote_full, 16);
clc_try_cancel(clc_response_addr + issue_stage * 16, clc_full_mbar_addr + issue_stage * 8);
}
}
}For the rest of the kernel, the changes are minor. Instead of while(get_next_tile), each warp will now have the outer loop be continually run with while(true). Pre-first iteration of the loop each warp type will calculate its needed block row, col by using its blockIdx.x. Then after completing its logic each warp will wait on clc_full_mbar then query the response to receive the validity of the next tile and the new CTA id. The entire loop will terminate when the CLC response is not valid, meaning that the tile queue is empty.
// Initial tile from blockIdx
int packed = tile_map[blockIdx.x / CTA_GROUP_SIZE];
int block_col = packed & 0xFFFF;
int block_row = (packed >> 16) * CTA_GROUP_SIZE + cta_rank;
// producer
if (warp_id == producer_warp_id && elect_sync())
{
while (true)
{
// producer logic
mbarrier_wait(clc_full_mbar_addr + clc_stage * 8, clc_full_phase);
uint32_t is_valid, new_ctaid;
clc_query_response(clc_response_addr + clc_stage * 16, is_valid, new_ctaid);
mbarrier_arrive_cluster(cta0_clc_empty_addr + clc_stage * 8);
clc_stage = (clc_stage + 1) % NUM_CLC_STAGES;
if (clc_stage == 0) clc_full_phase ^= 1;
if (!is_valid) break;
}
}
// consumer
else if (cta_id == 0 && warp_id == consumer_warp_id && elect_sync())
{
while (true)
{
// consumer logic
mbarrier_wait(clc_full_mbar_addr + clc_stage * 8, clc_full_phase);
uint32_t is_valid, new_ctaid;
clc_query_response(clc_response_addr + clc_stage * 16, is_valid, new_ctaid);
mbarrier_arrive_cluster(cta0_clc_empty_addr + clc_stage * 8);
clc_stage = (clc_stage + 1) % NUM_CLC_STAGES;
if (clc_stage == 0) clc_full_phase ^= 1;
if (!is_valid) break;
}
}
// epilogue
else if (warp_id < NUM_EPILOGUE_WARPS)
{
while (true)
{
// epilogue logic
mbarrier_wait(clc_full_mbar_addr + clc_stage * 8, clc_full_phase);
uint32_t is_valid, new_ctaid;
clc_query_response(clc_response_addr + clc_stage * 16, is_valid, new_ctaid);
if (elect_sync())
{
mbarrier_arrive_cluster(cta0_clc_empty_addr + clc_stage * 8);
}
clc_stage = (clc_stage + 1) % NUM_CLC_STAGES;
if (clc_stage == 0) clc_full_phase ^= 1;
if (!is_valid) break;
packed = tile_map[new_ctaid / CTA_GROUP_SIZE];
block_col = packed & 0xFFFF;
block_row = (packed >> 16) * CTA_GROUP_SIZE + cta_rank;
}
}Another benefit of the CLC-based scheduler is the tile issuance order. Our previous scheduler dealt the Hilbert-ordered tile list round-robin across the 74 clusters, so each cluster's local sequence advanced with a stride of 74. This weakened Hilbert locality and reduced the L2 hit rate. With CLC, feeding each tile as each output tile finished, the average stride between consecutive tiles is far less than 74 so the consecutive tiles land closer in the Hilbert curve, which leads to more A-row and B-column overlap, which causes the increased hit rate. As a result, the CLC-based scheduler improves our L2 hit rate by 9.65 percentage points from 64.89% to 74.54%, which is also higher than cuBLAS's L2 hit rate of 71.91%.
Memory Workload Analysis
| Memory Throughput [Gbyte/s] | 962.14 | Mem Busy [%] | 33.20 |
| L1/TEX Hit Rate [%] | 61.00 | Max Bandwidth [%] | 51.33 |
| L2 Hit Rate [%] | 74.54 | Mem Pipes Busy [%] | 94.28 |
Now we are reaching about 99.0% of cuBLAS's performance on average, a 7.1-point gain over v7, while reaching 106% at M=N=K=8192.
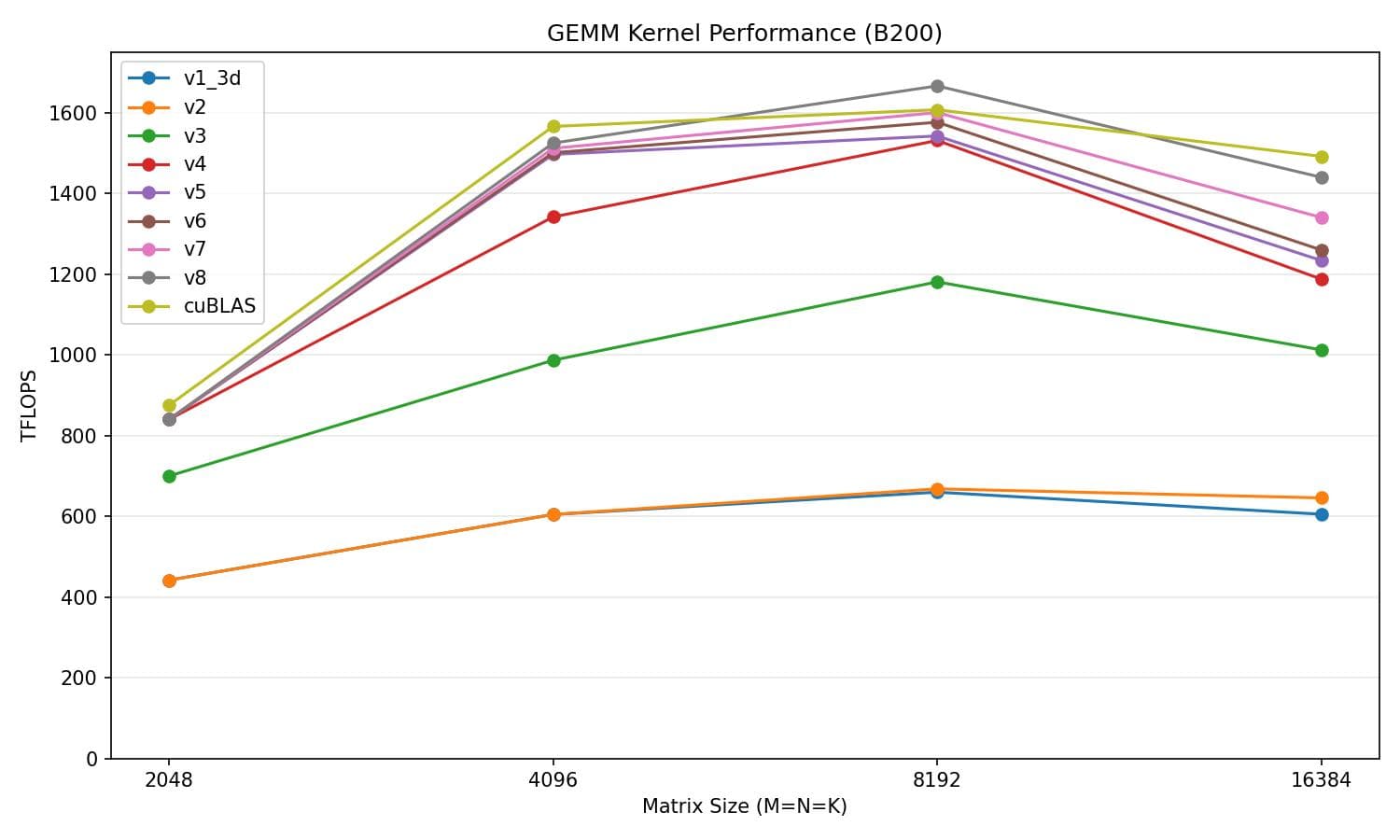
v8 vs cuBLAS
| Matrix size | v8 (TFLOPS) | cuBLAS (TFLOPS) | % of cuBLAS |
|---|---|---|---|
| 2048 | 761.5 | 838.9 | 90.8% |
| 4096 | 1527.4 | 1520.5 | 100.4% |
| 8192 | 1646.7 | 1551.0 | 106.2% |
| 16384 | 1402.3 | 1424.8 | 98.4% |
Conclusion
Thank you so much for reading this far! Across 8 kernel versions we went from about 44% of cuBLAS on average to 99%, even beating cuBLAS at M=N=K=8192. I really enjoyed getting to work on these low level performance optimizations and especially love getting to showcase and illustrate them. All of the code is here on Github.
Special thanks to:
- Gau-nernst for his tcgen05 writeup, which served as the basis for the initial kernel and the intra-kernel profiler.
- Pranjal whose H100 worklog was the direct inspiration for this post.
- Modular for their Blackwell blog post series, which documented Cluster Launch Control better than any other source I could find.
- MXFP8 GEMM: Up to 99% of cuBLAS performance using CUDA + PTX — a really detailed lower-precision GEMM implementation on Blackwell.
- Strangely, Matrix Multiplications on GPUs Run Faster When Given "Predictable" Data! — for the framing around power as a constraint.
- "This Kernel Was Faster Yesterday" — In Pursuit of High-Fidelity GPU Kernel Benchmarking — great ideas for benchmarking CUDA kernels.
- Nvidia's B200: Keeping the CUDA Juggernaut Rolling — source of the B200 specifications.
- Tensor Memory Accelerator Guide — more specifics on how the TMA works.
- Blackwell Cluster Launch Control with CUTLASS — official details from NVIDIA on CLC.
- DeepGEMM — inspiration for the optimized epilogue.
Benchmarking
The benchmarking was done on Modal with the following details:
- B200 GPU, 1000W power
- CUDA 13.0.2, Ubuntu 24.04, Python 3.12
- PyTorch version: 2.9.1+cu130
- bf16 outputs