February 28, 2026
NVIDIA's True Moat in the Compute Wars: TSMC
Nvidia's moat is typically recognized as its CUDA software stack and ecosystem, but its true moat lies in its special relationship with TSMC. Having a relationship with TSMC is nothing out of the ordinary, as Nvidia, AMD, Google (TPU), and most ASIC providers all source greater than 90% of their wafers from TSMC. Yet, Nvidia's relationship with TSMC is far more than one of a customer to a provider. By leveraging its utter dominance of the datacenter-GPU market, Nvidia has been able to effectively dominate the allocation of both current TSMC wafer and packaging capacity and incremental capacity. As a result, any competitors seeking to ramp production of their GPUs find their potential production increases stifled and limited as they simply cannot get the necessary wafer allocation from TSMC.
TSMC's Shifting Allocation
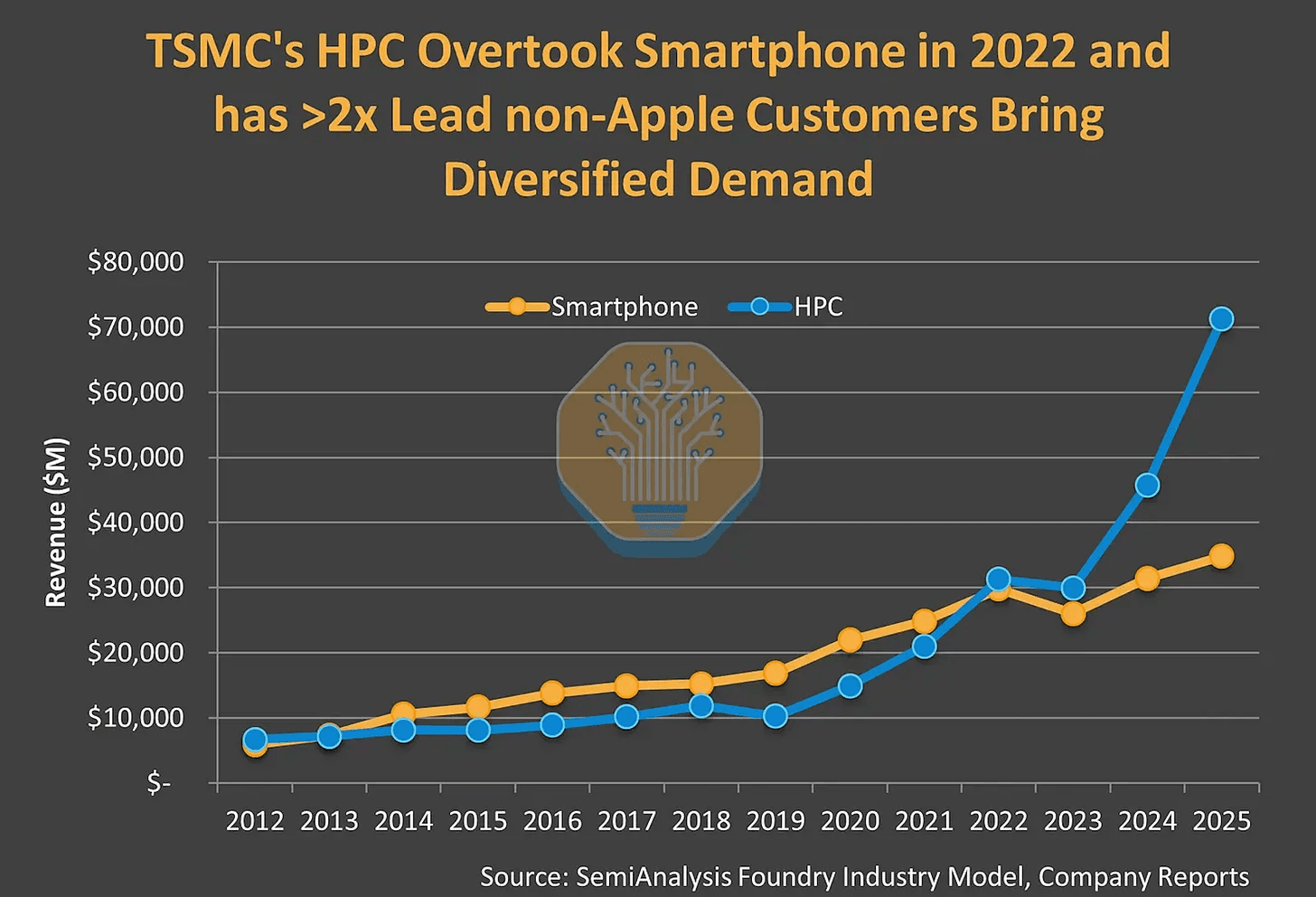
Historically, TSMC's fabrication business as been a mix of smartphone and HPC demand, yet since the emergence of LLMs into the minds of the general public, that has changed. HPC or rather GPUs have grown to dominate while smartphone demand remains consistent but with far more tepid growth. Especially with the current memory super-cycle destroying demand for smart phones, the trend lines point to HPC continuing to trounce smartphones in allocation at TSMC. Nvidia being the world's largest company and commanding a 85% share of the data-center GPU market represents a significant percentage of this newfound HPC growth. The extent of this growth has fundamentally altered the balance of power in TSMC's allocation reasoning and illustrates why Nvidia can hold this sway at TSMC.
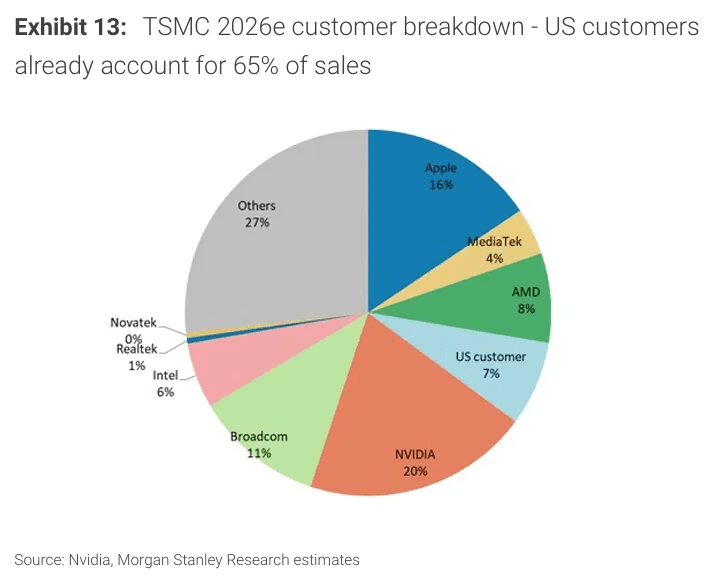
In 2026, Nvidia officially became TSMC's largest customer by revenue contribution percentage. Towering above AMD with a roughly 2.5x gap (even without disaggregating AMD's CPU and GPU businesses) and edging out Apple, who had been TSMC's anchor customer since its 20nm node in 2013. Being the largest customer comes with more than just the title, as TSMC prioritizes customers by size. This leverage is critical in negotiations, specifically in regards to allocation. Essentially, the revenue share leaderboard is the line order when it comes to distributing wafer allocation. Being the largest customer or rather anchor customer comes with additional benefits. As the loss of the anchor customer crown and its benefits is evident in TSMC's recent dealings with Apple. MacRumors reported in November, 2025, that TSMC had notified Apple of 8-10% price hikes in its A16, A17, A18, A19, M3, M4, and M5 chips. Though it appears that Nvidia's benefits have less to do with wafer costs and more to do with CoWoS.
CoWoS: The Packaging Bottleneck
When it comes to GPUs, wafers are only half of the story. The key bottleneck in GPU computation is memory, where with each generation the gap between performance of cores outgrows the increases in memory bandwidth. Packaging GPUs with HBM (high-bandwidth-memory) is emerging as central to both GPU performance and to TSMC's business. It should come as no surprise that in this domain, Nvidia is even more dominant. CoWoS (Chip-on-wafer-on-substrate) is TSMC's proprietary 2.5D packaging technology that connects the GPU with HBM stacks in a maximally efficient configuration; by minimizing the physical distance between the compute die and HBM stacks as it increases memory bandwidth.
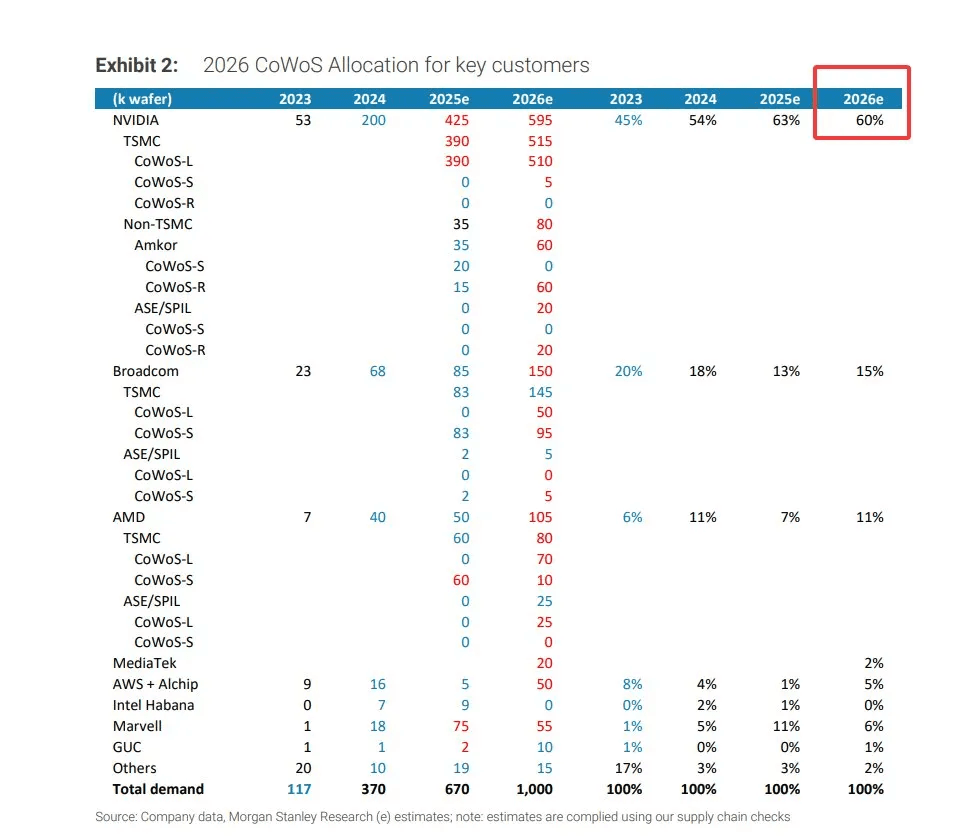
In 2023 CoWoS capacity was 117k wafers, in 2026 that will be around 1 million wafers, that is a 10x expansion in 3 years. Yet most of the growth in capacity has been taken by Nvidia as it has grown its allocation percentage by 33% in that same time period. While the absolute value of CoWoS packaging has grown, the level of incremental capacity that has been taken up by Nvidia has begun to crowd out its competitors. This is evident with Broadcom, as its CoWoS allocation percentage has been in decline since 2023. Even with renewed interest in TPU from neo-clouds and hyper-scalars alike, Broadcom is constrained in servicing this demand by being unable to acquire the necessary CoWoS packaging capacity.
AMD: The Biggest Loser
Though, there is no greater loser in this allocation battle than AMD.

Much ink has been shed on AMD's deals with OpenAI and Meta. With over 12 GW of compute planned to be deployed through 2031, it appears that AMD may will challenge Nvidia, that is if they can ramp production.
The Allocation is not Sufficient
Both deals have the identical structure of 1 GW of GPUs being deployed in H2 2026 and the rest through 2031. The first deployments will be with the MI450 or Helios racks, so we will use the MI450 for calculating the actual amount of GPUs, and thus wafers, that need to be shipped. While neither deal explicitly mentions the number of GPUs, given that both deals involve the MI450, we can use Oracle's deal with AMD as a guide.

Oracle notes that these 50,000 MI450s will consume around 200 megawatts when fully connected. That would be about 200MW / 50,000 = 4kW per GPU when interconnected at the system level or around 288kW per Helios rack (72 GPUs). If we scale that to both the Meta and OpenAI deals we get:
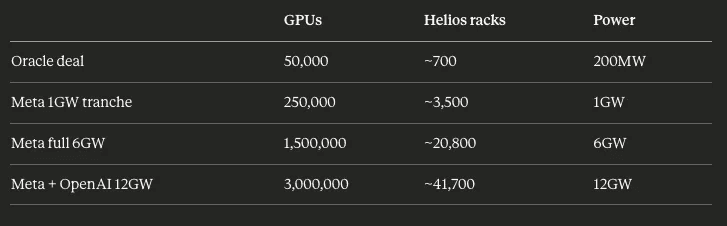
Each MI450 isn’t a single monolithic chip, rather its a multi-chiplet package that is assembled together with CoWoS-L packaging. The number of finished packages that are required is mainly dictated by interposer size, which is the silicon substrate that is beneath the compute dies and HBM stacks. As the transposer size is not public, it could range from 3.5x to 5.5x reticle depending on chiplet configuration and HBM stack count, with the associated packages per wafer shifting with that ratio. While the exact number of chips per CoWoS-L wafer is not public, we can estimate using 9 chips per CoWoS wafer which is the average across comparable Nvidia products.
With that we get:
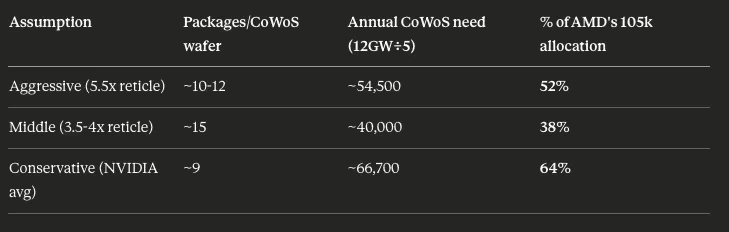
Depending on the actual chip to CoWoS wafer the amount of CoWoS allocation required for these two deals can vary. Yet, it is clear that they will represent a significant amount of AMD's allocation for the foreseeable future. With AMD GPU demand ramping in other areas, notably gaming, it doesn't appear that there is another incremental 50k CoWoS wafers of capacity that are available. Of course if AMD could get more TSMC allocation this wouldn't be an issue, but if history is any guide, where Nvidia took the lions share of allocation before it was an anchor customer, it seems doubtful that it wouldn't repeat this same move as the top customer. The math simply doesn't add up for AMD to fulfill these deals with its current level of allocation.
A Structural Barrier
Ultimately, Nvidia's supply chain dominance has yielded an ecosystem that generates far more of a moat than the CUDA stack ever could achieve. Through becoming TSMC's anchor customer, reserving incremental wafer capacity, and absorbing CoWoS expansion, Nvidia has turned TSMC's supply constraints into a structural barrier for other compute providers.